Bearweb Memory Optimization
PHP optimization on the Bearweb CMS to reduce memory usage and chance of OOM.
Bearweb, PHP, Memory usage, Memory optimization, File size, OOM, Out of memory, Output buffer, RAM, stream
--by Captdam @ Feb 2, 2026Index
Resource Size
A resource is a piece of data on the website. A resource can be HTML code for a webpage; a binary multimedia file such as image and video; a JavaScript or CSS code that controls front-end behavior. A resource can be addressed using a URL. When the user types a specific URL into the URL bar in the browser, the browser will download the resource represented by that URL from the server to the client-size and display it. If that resource is a HTML, CSS or JavaScript code, the browser may parse it and download more resources as requested by its content.
An important metric for resources is size. A large resource can hold more information, or a better quality of the information; but consumes more storage space on the server and more bandwidth when downloaded to the client. As a site administrator, I have to ask myself:
- How much storage space am I going to allocate to a resource?
- How much network bandwidth am I going to pay for the visitor to download it?
- How much patience does the visitor have to wait for a resource to be downloaded?
HTML Webpage
A webpage is stored in the underlying HTML code in a .html file. This file includes the text content and structure of the webpage. It also holds other information such as links to CSS and JS files; but in most cases, they only consume a limited space of the HTML file.
Most HTML files range from a few thousand bytes, and in some extreme cases, to some hundreds of kilobytes. That is enough space to store a middle-length novel. Reading a page with this much text can take a human half an hour. For example, reading a Wikipedia page about HTML takes about one hour, the size of that page is about 90kB. However, storing that much information only takes a negligible amount of disk space. Downloading that much information using today’s network bandwidth happens in the blink of an eye.
Therefore, I am not worried about HTML files at all.
Multimedia
Media resources, like images and videos are another story. They are large in size, and slow to download.
Diagram and Drawing
Diagrams and (engineering) drawings can be easily compressed, because they hold limited information.
One way to compress them is to use SVG image format. It records how to draw an image, instead of the color of each pixel. Therefore, a SVG image can be very large in resolution, but small in the SVG file size.
Another way is to use indexed PNG. It uses an internal index to record pixel color. For images with large amounts of blank and limited color (low data density), using indexed PNG can reduce the file size.
SVG and PNG are definitely the first option I will pick to store diagrams and drawings. They consume less storage space on my server, less bandwidth to transfer, and less wait time for the visitor.


Above example shows the same image can be compressed into half the orginal size using indexed color mode. It may lose some color, but this is acceptable for diagrams and drawings. Click the image to zoom in to see the detail.


Above example shows the same image if saved in JPEG. Higher quality looks OK (but still blur), but is too large; lower quality saves space, but looks poor. Click the image to zoom in to see the detail.
Photo
Photography is different from diagrams and drawing. Each pixel of a photo holds some information. The best way to compress a photo is to reduce the amount of data in each pixel, by saving them in a JPEG file with reduced quality.
Using SVG or PNG is not favoured.
In my experiments and opinions, an excellent photo should have quality above 90%; a good photo should be above 70%; and a so-so photo should be at least 30% to 40%. In some cases, color is not important, going lower quality still rendering an acceptable result.
When zoom in a low quality image, you will find the color is very inaccurate, and extreme significant color gap between each 8*8 blocks.

Above is a photo of a cosplayer in "RAW" PNG format. Following examples shows the same photo in JPEG format with different quality settings:


Using JPEG with 90% quality reduce the file size by 85%, compared to the PNG file. Using JPEG with 70% quality future reduce the file size by half.
As we can see, reducing the quality has an insignificant negative visual effect but saves a great deal of file size.
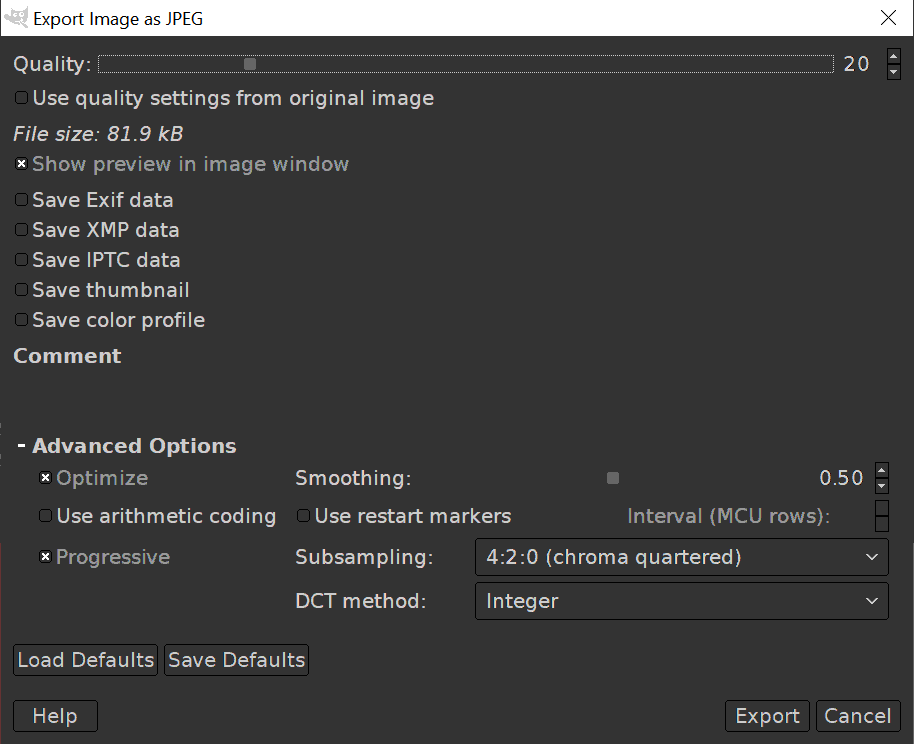
In GIMP, when exporting an image as a JPEG file, I am able to make future optimization. Smoothing can reduce the file size and the color gap. 4:2:0 subsampling can future reduce the file size at the cost of color accuracy.


Above shows the same image saved in low quality JPEG format with 4:2:0 subsampling. Depending on the application, the quality may be acceptable or too poor. Pay attention to regions where both high-frequency and low-frequency exist, like fingers.
Video
No! Let YouTube pay for the storage and bandwidth.
Offload Large Blob from DB to File System
Database-driven CMS
I had written a CMS (Content Management System), Bearweb, to power my blog (this website). Bearweb CMS is database-driven. The DBMS I choose is SQLite.
The structure of Bearweb CMS is to store each resource into a relational database called sitemap. Each row represents a resource, whereas the url of that resource (for example: dir/to/resource.html) served as the PK (Primary Key). Inside that row is the metadata of that resource, such as create time, last modify time, and the content of that resource.
I originally designed my website to demonstrate my developments. I occasionally include some images to show an idea, like engineering drawing and flow diagram. Those images are small.
Some of these images can be encoded into SVG, which takes a few kilobytes; some of them can be compressed using indexed-color PNG, which takes around 10 to 50 kB each.
As I add more articles into my blog, so will the database size grow. This is not too bad. Even with a few hundreds of images, the database size is still manageable. For example:
50kB * 500 images = 25000kB = 25MB
That’s not terribly bad. Today’s disk is large enough, the network is fast enough.
Even when I need to download the entire database into my local computer, make some changes, then upload the database back to the server, my network bandwidth can handle this task in seconds.

Later, I decided to add posters on each of my articles, such as a photo of my PCB. These (photo-like) images must be saved in JPEG format for a reasonable file size.
A 2K resolution photo in JPEG format with 40% quality can take about 50kB to 200kB (in above example: JPEG quality 40 subsampling 420: 2000 x 1417 px 24-bit RGB 127kB). In fact, 40% quality is pretty poor. I will need to bump the quality to 70% to save a beautiful image.
Since I use the photo for cosmetical purposes only, I am OK with poor quality to compensate for storage space and download speed. However, even with image quality tradeoff, putting all images (and other multimedia resources) into a single database file still renders the database file too big.
Recently, I helped my photographer friend to build a personal blog. Image quality is not a big deal for my development site, but very important for him. Most of his photos exceed 8K resolution and need very high quality.
That means, an image can easily go beyond 10MB in size.
Most of his photos range from 20MB to 35MB in PNG format.
If I store all the images in the database, it will be a nightmare for database maintenance.
Database vs File System
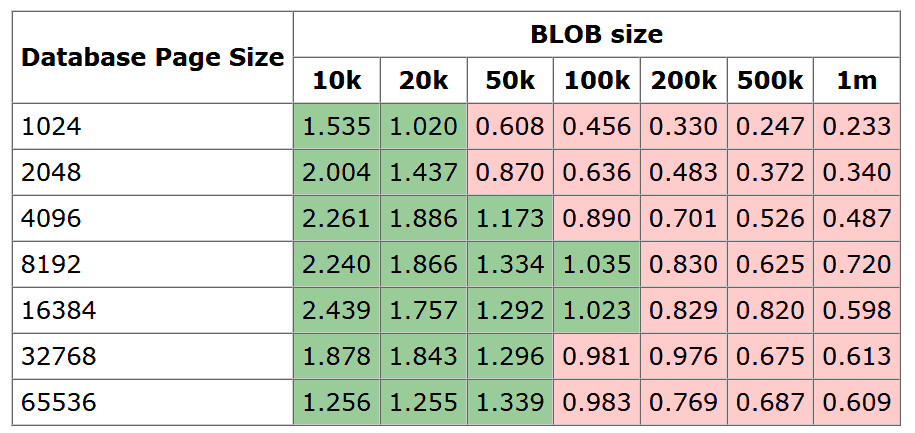
The official SQLite document Internal Versus External BLOBs in SQLite also recommends offloading large blobs (larger than 100kB) from the database into the file system.
Although the actual performance may vary depending on the underlying machine, I decided to follow the 100kB threshold. To me, the gain is not really how fast the file system read will be compared to database read, it is how fast I can download and upload the database file during maintenance.
I have to ask myself, what is the benefit of storing the data in a database only compared to in a file system?
- It saves a file open system call. Only one call to open and read the database to get the metadata and the
content. Compared to one call to the database for the metadata, followed by another call to the file system for thecontent. - Can compress multiple small files together; where on a file system, each file must consume the minimal file size. The advantage is for small resource
- Allows full-site
contentsearch. The advantage is for text resource
Do large blobs (like images) need them?
No!
In conclusion, I will have to offload large blobs from the database into the file system.
We will call a resource database-backed resource or a file-backed resource based on:
| Properties | Database-Backed | File-Backed |
|---|---|---|
| Size | Less than the threshold (100kB) | Greater than or equal to the threshold (100kB) |
content saved in |
Database | File system |
content field in database |
A (binary) string representing the content data |
null |
Flat vs Hierarchical File System
Assume there is an article with URL /article/bear. In this article, there is an image with URL /article/bear/photo.jpg.
In relational databases (like SQLite, MySQL, etc.), all resources (rows) are stored in a flat fashion. In other words, the article /article/bear and the image /article/bear/photo.jpg can coexist.
However, in the file system, files are stored hierarchically. To store the image /article/bear/photo.jpg, the file system will need to create a directory named /article/bear, then store the image /article/bear/photo.jpg in this directory. At this point, because the directory /article/bear already used this pathname, there is no way to store the article /article/bear as a file.
If we store the article /article/bear first as a file; then, when we need to store the image /article/bear/photo.jpg, we cannot create the the directory /article/bear for it, because that pathname is already used as a file.
We can think the file system in this way. Under a directory, there are files can be read, write and executed. A subdirectory is a special executable file. Executing this file leads us to the content of this subdirectory.
It is common to see / (slash character) in the URL. The file system uses this character to build a file system hierarchy. It is wise for the file system to use hierarchical design; it separates the size of the file system into each level of the hierarchy. In a flat file system, accessing a file requires looking up a extremely large file list; in a hierarchical file system, accessing a file requires recursively looking up small file list (which means fast) at each level.
For us, the hierarchical design in file systems not only prevents us from storing a resource whose pathname is part of another; but also makes our code design more complex, because we will need to differentiate directory and file.
We will use another special character # (hash) to replace the original / in URL when we need to access files in the file system. The # character will be treated as separator between the file pathname and tag id in URL; hence, there should be no # in the file pathname part in a URL. On the other hand, # is allowed in file pathname in most file systems.
class Bearweb_Site {
const Dir_Resource = './resource/';
protected static function __file_path(string $url): string { return static::Dir_Resource.str_replace('/', '#', $url); }
}
This converts a hierarchical URL into a flat URL.
After the conversion, /article/bear becomes resource/article#bear, /article/bear/photo.jpg becomes resource/article#bear#photo.jpg. There will be no sub-directory under the resource/ directory. Both resources can coexist.
Another way is to use object storage, which also uses flat design. However, I don’t want to deploy a local object storage server nor connect to an external object storage. It introduces another layer of complexity and makes my codebase less portable.
Reading and Writing Both Database and File System
When everything including the content is saved in the database, reading a resource is just a select to the sitemap database; writing a resource is just an update to the sitemap database; deleting a resource is just a delete to the sitemap database.
Now, the sitemap database is still here. There is no change on small resources (like HTML pages), everything is still saved in the database; however, large for resources (like large images), only the metadata is stored in the database, the content (which exceeds the 100kB threshold) will be saved in the file system, use the resource url as filepath.
Instead of using a simple select, update or delete call to the sitemap database when reading, writing or deleting a resource, and relay on the underlying DBMS to ensure the ACID properties. We will need to use transaction control to make sure the ACID properties across both the DBMS and the file system:
- Atomicity: In a transaction, change will be made to the database first, but not commit. Change is then made to the file system. If the file write / delete is successful, the change to the database will be committed. Otherwise, the change to the database will be rolled back. For SQLite using rollback janaury, write modifies database file, commit deletes rollback january; therefore, commit should always be successful, unless a power failure or system crash occurs after file write / delete but before database commit, which is not likely to happen on a server.
- Consistency: This should be easily achievable using today’s server hardware.
- Isolation: Both the database and the file system use read / write lock.
- Durability: This should be easily achievable using today’s server hardware.
We will assume that the read and write to file system should either succeed, or fail. If we can open this file in read mode, the reading should be successful and the entire content can be successfully read into memory. If we can open a file in write mode, the writing should be successful and the entire content would be successfully saved to disk. There is no failure at midpoint.
Furthermore, when making any change, the user who initiates that change should check back the result to confirm the change is made successfully.
Changes to Bearweb CMS Sitemap Database Access
If the content saved in database is a string (batabase-backed resource), the string will be the actual content data. If the content is null (file-backed resource), that means the content is saved in file system.
The content instance variable
class Bearweb_Site {
public string $url;
... // Other metadata
public mixed $content { // resource|string
get => is_string(get_mangled_object_vars($this)['content']) ? $this->content : $this->__file_read(-1);
}
}
The content in a resource can be:
- Database-backed: A
stringwhich holds the actual data of this resource. Note in PHP,stringcan be binary string. - File-backed: A
resource(PHP file pointer) which points to the file holding the actual data of this resource.
PHP does NOT support resource as a type. Therefore, we have to use mixed instead of resource|string for content type.
When use content:
- Database-backed: The data saved in variable
string contentis returned. - File-backed: Return the file content in the file pointed by
resource content.
PHP 8.4 introducesd property hook to allow us to create getter and setter for class properties. Using the getter in this example automatically read the actual content data from file, if the resource is file-back.
We must use get_mangled_object_vars($this)['content'] to get the raw data of the instance variable content. It is a resource for file-backed resource; or a string for database-backed resource.
Using $this->content returns the hooked (getter) value of content, which will always be string. Even if the resource is file-backed, the getter will load it from the file system and return the content in string.
Read
class Bearweb_Site {
public static function query(string $url): ?static {
try {
$sql = static::$db->prepare('SELECT * FROM `Sitemap` WHERE `url` = ?');
$sql->bindValue( 1, $url, PDO::PARAM_STR );
$sql->execute();
$site = $sql->fetch();
$sql->closeCursor();
if (!$site)
return null;
$site['content'] = $site['content'] ?? fopen(static::__file_path($site['url']), 'rb');
return new static(...$site);
} catch (Exception $e) { throw new BW_DatabaseServerError('Cannot read sitemap database: '.$e->getMessage(), 500); }
}
}
To read a resource:
- Read the resource from the database. If database read failed, throw an exception. No file opened in this case.
- If the returned
contentisnullin the database, that means thecontentis saved in the file system. - Then, open the file in read-only binary mode. If file open failed, throw an exception. The result from database read will be discarded in this case.
We opened the file in read-only mode. This allows us to implement file access control on file system level. For example, we can make an image read-only to Apache user (www-data). Read this image will success; but write will fail.
For file-backed resource, the content file is opened. However, it is read only when required (lazy-read). This should save file system read cost if the content is not used.
Insert and Update
class Bearweb_Site {
const Size_FileBlob = 100000;
public function insert(): void { try {
static::$db->beginTransaction();
try {
$sql = static::$db->prepare('INSERT INTO `Sitemap` (`url`, `...`, `content`) VALUES (?, ?, ?)');
$sql->bindValue(1, $this->url, PDO::PARAM_STR );
$sql->bindValue(2, ..., ... );
if (strlen($this->content) >= static::Size_FileBlob) {
$sql->bindValue(3, null, PDO::PARAM_NULL);
} else {
$sql->bindValue(3, $this->content, PDO::PARAM_STR);
}
$sql->execute(); // Not committed yet
if (strlen($this->content) >= static::Size_FileBlob) {
$this->__file_write();
} else {
$this->__file_delete();
}
static::$db->commit();
} catch (Exception $e) {
static::$db->rollBack();
throw $e;
}
$sql->closeCursor();
} catch (Exception $e) { throw new BW_DatabaseServerError('Cannot insert into sitemap database: '.$e->getMessage(), 500); } }
public function update(): void { try {
static::$db->beginTransaction();
try {
$sql = static::$db->prepare('UPDATE `Sitemap` SET `...` = ?, `content` = ? WHERE `URL` = ?');
$sql->bindValue(1, ..., ... );
$sql->bindValue(3, $this->url, PDO::PARAM_STR );
if (strlen($this->content) >= static::Size_FileBlob) {
$sql->bindValue(2, null, PDO::PARAM_NULL);
} else {
$sql->bindValue(2, $this->content, PDO::PARAM_STR);
}
$sql->execute(); // Not committed yet
if (strlen($this->content) >= static::Size_FileBlob) {
$this->__file_write();
} else {
$this->__file_delete();
}
static::$db->commit();
} catch (Exception $e) {
static::$db->rollBack();
throw $e;
}
$sql->closeCursor();
} catch (Exception $e) { throw new BW_DatabaseServerError('Cannot update sitemap database: '.$e->getMessage(), 500); } }
}
For insert and update a large resource (file-backed):
- Start a transaction.
- Write metadata into the database, assign
nullto thecontentcolumn. If database write failed, throw an exception. No change committed to database, and the file system untouched. - Write
contentinto the file. If file write failed, throw an exception. Since the database write has not been committed yet, we can rollback it. - Commit the transaction.
For insert and update a small resource (database-backed):
- Start a transaction.
- Write the resource into the database. If database write failed, throw an exception. No change committed to database, and the file system untouched.
- Unlink the file (if existed), in case this was a file-backed resource. If file delete failed, throw an exception. Since the database write has not been committed yet, we can rollback it.
- Commit the transaction.
Delete
class Bearweb_Site {
public function delete(): void { try {
static::$db->beginTransaction();
try {
$sql = static::$db->prepare('DELETE FROM `Sitemap` WHERE `URL` = ?');
$sql->bindValue(1, $this->url, PDO::PARAM_STR );
$sql->execute(); // Not committed yet
static::__file_delete();
static::$db->commit();
} catch (Exception $e) {
static::$db->rollBack();
throw $e;
}
$sql->closeCursor();
} catch (Exception $e) { throw new BW_DatabaseServerError('Cannot delete blob file from sitemap database: '.$e->getMessage(), 500); } }
}
To delete a resource:
- Start a transaction.
- Delete the row for that resource in the database. If database write failed, throw an exception. No change committed to database, and the file system untouched.
- Unlink the file (if existed), in case this was a file-backed resource. If file delete failed, throw an exception. Since the database write has not been committed yet, we can rollback it.
- Commit the transaction.
Changes to Bearweb CMS Resource File System Access
Next, we will need to implement file system transaction control into the database transaction control:
Read
class Bearweb_Site {
protected function __file_read(int $len = -1) {
$file = get_mangled_object_vars($this)['content'];
flock($file, LOCK_SH);
if ($len < 0) {
fseek($file, 0, SEEK_END);
$len = ftell($file);
if ($len === false)
throw new BW_DatabaseServerError('Cannot get size for blob file: '.$this->url, 500);
}
rewind($file);
$content = fread($file,$len);
if ($content === false)
throw new BW_DatabaseServerError('Cannot read from blob file: '.$this->url, 500);
flock($file, LOCK_UN);
return $content;
}
}
A shared lock (read lock) should be obtained before the reading. This is to prevent that another process may be writing the same file at the same time. The PHP process will wait until the read lock can be obtained. If it cannot obtain the read lock within a specific time period, the PHP script will be killed due to timeout. In this case, no read is performed.
This may happen if the site is extremely busy (long time write the same resource. Read is fine, because it is shared (read) lock); or when there is an interlock in the code (the developer drunk too much). Both are rare. If really happened, Apache will return an error.
After the read lock obtained, we can to read len bytes of data from the file. If len is negative, we will have to measure the size of the file first.
At the end, release the lock to allow write on this file from another process.
Release the lock immediately after it is no longer used. This allows another process to obtain write lock as soon as possible, reduce the wait time.
File lock will be automatically released after the script exit. So, it is OK to omit lock release in case of error occurred (error is not likely to happen) if we don't want to write too much code.
Write
class Bearweb_Site {
protected function __file_write(): void {
$file = fopen(static::__file_path($this->url), 'wb');
flock($file, LOCK_EX);
rewind($file);
if (fwrite($file, $this->content) === false)
throw new BW_DatabaseServerError('Cannot write to blob file: '.$this->url, 500);
flock($file, LOCK_UN);
fclose($file);
}
}
When write a resource, the instance variable content holds the data to write. We create a new write pointer using fopen(path, 'wb') at the beginning.
A exclusive lock (write lock) should be obtained before the writing. This is to prevent that another process may be writing or reading the same file at the same time. The PHP process will wait until the write lock can be obtained. If it cannot obtain the write lock within a specific time period, the PHP script will be killed due to timeout. In this case, no write is performed.
After the write lock obtained, we can start to write the content into that file. In case the write failed, throw an exception.
At the end, release the lock to allow read / write on this file from another process.
Delete
class Bearweb_Site {
protected function __file_delete(): void {
$path = static::__file_path($this->url);
if (!(is_file($path) ? unlink($path) : true))
throw new BW_DatabaseServerError('Cannot unlink blob file: '.$this->url, 500);
}
}
Delete the file if existed.
If delete failed, throw an exception.
Linux manual page said: unlink() deletes a name from the filesystem. If that name was the last link to a file and no processes have the file open, the file is deleted and the space it was using is made available for reuse. If the name was the last link to a file but any processes still have the file open, the file will remain in existence until the last file descriptor referring to it is closed.
Than means, if we delete (unlink) the file opened by another process, the file system will keep this file, until no process has it opened. Therefore, we do not need to exclusively lock this file. A process still accessing this file can continue.
Memory Consumption
An OOM (Out of Memory) Incident
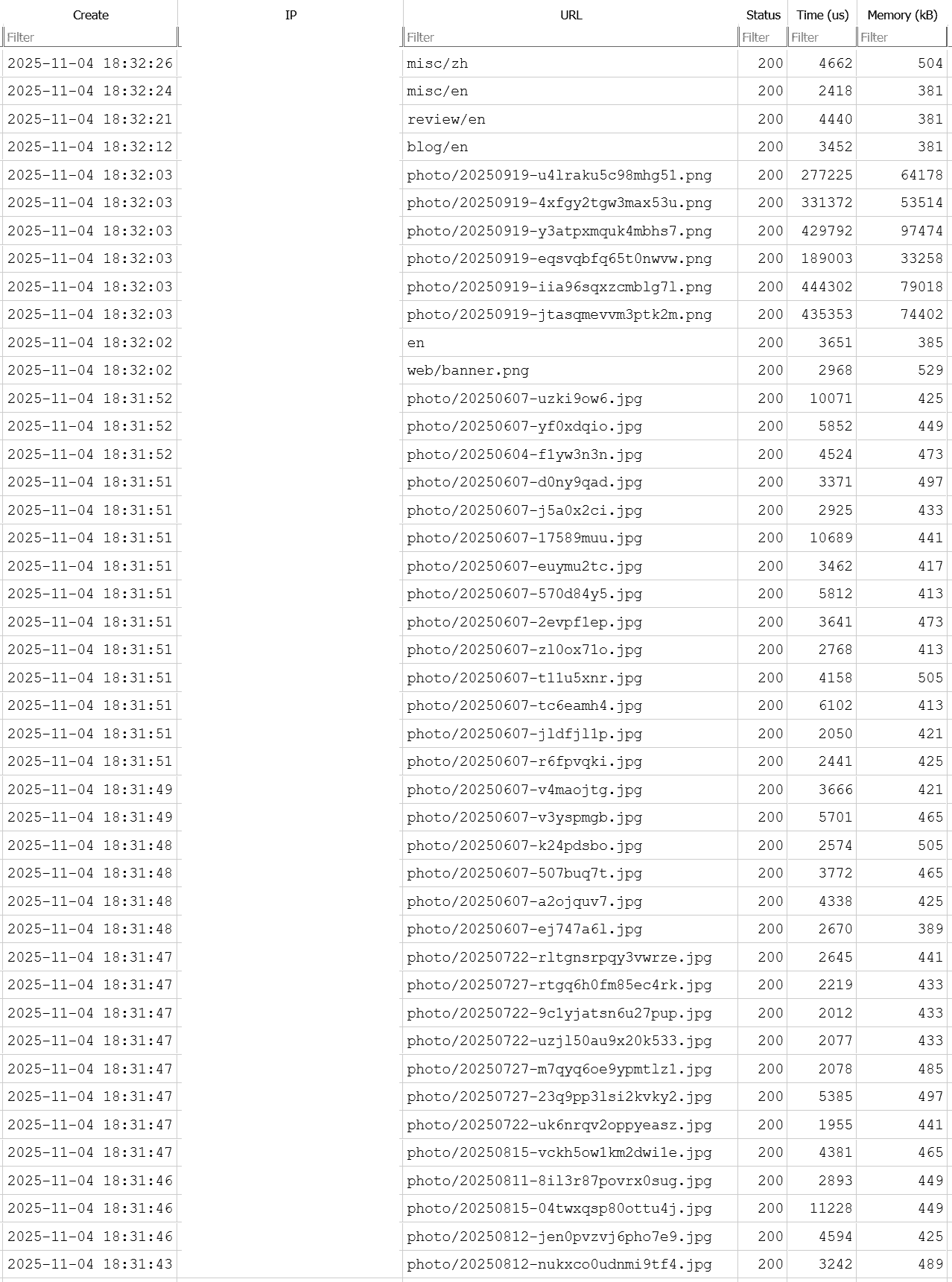
A recent (possible DDos) incident took my website down. After investigation, it is clear that a few HTTP requests on the large image resources caused the server to run out of memory (OOM-killed).
Luckily, I do record time and memory consumption for each request.
For a HTTP request served by my Bearweb CMS, the RAM consumption is contributed by 3 parts:
- A fixed amount of around 300kB. This includes not only the variables I used in my PHP scripts; but also the underlying Apache and PHP engine, the PHP scripts.
- The resource
contentis loaded into RAM. - Output buffer. This buffer will be the same size as the resource.
For example, to serve a 30MB PNG image, the memory consumption is:
300kB + 30MB + 30MB = 60.3MB
That’s insane. A server with 1GB RAM can only serve around 15 requests at the same time, or the Apache will be killed by the OS due to memory shortage.
In most senorial, my site doesn’t have too many visitors; hence, less chance of simultaneous requests. Furthermore, most requests are requesting small resources (HTML pages, JS scripts, small-size thumbnail images); hence, even with large amounts of simultaneous requests, the total RAM usage is low. On the other hand, requests are served fast, even some requests consume lots of RAM, new requests may arrive after the previous requests were already processed (and the memory freed). Therefore, the total RAM consumption is not high.
This time, it is a few simultaneous requests, all requesting large-size resources, causes the RAM usage to spike.
I had my website running for almost 10 years. This is the first time I experienced an OOM incident.
Resource Size
The most obvious way is to reduce resource size.
A 30MB image does look pretty; however, it is not appropriate to share it on a website. Most visitors just open and close the image. I don’t think anyone uses a magnifier to view images.
Therefore, it’s not worth it to serve a large-size best-quality image on a website. Instead, a compressed, OK-quality image could be a better choice. In my opinion, 10MB should be good balance between image quality and size.
Compared to a 30MB image which consumes 60MB of RAM, a 10MB image will only consume 20 MB of RAM, without any future optimization.
Server Number
Apache uses multiple worker to serve requests simultaneously.
The reason for the OOM incident is because too many simultaneous requests consumes too much RAM in total.
We can reduce the maximum number of servers, which reduces the number of simultaneous requests. If there is a spike in request, excessed requests will be saved in the input queue and be processed later.
I made change to the Apache config file mpm_prefork.conf:
<IfModule mpm_prefork_module>
StartServers 5
MinSpareServers 5
MaxSpareServers 10
MaxRequestWorkers 40
MaxConnectionsPerChild 1000
</IfModule>
Given the 32MB memory limit (in PHP) for each request, 40 simultaneous requests will consume at maximum 1.2GB RAM. This is the combination of my free memory and swap space on my server.
In detail, most requests only consume a negligible amount of RAM (less than 1MB), all requests can be served using the physical RAM only. In case of a spike in requests to large resources, some requests will have to use swap. The swap is slow, but can be used to prevent OOM. I treat swap as a backup of RAM.
Someone suggests using the avarage memory comsuption per worker to calculate worker number. I use the maxmium memory comsumption per worker to calculate the worst case senorial.
I also set the MaxConnectionsPerChild to 1000 to prevent memory leak. A worker will be killed after it serves 1000 requests. It is not really necessary, just to play it safe.
Output Buffer
Using output buffer has a few advantages:
- Instead of sending multiple small segments of data, flushing them all together at the end will reduce the time of sending; hence speed up the process. By reducing the time to serve each request, it also decreases the number of simultaneous requests.
- Allows cleaning the buffer and reloading new data. For example, when an error occurred, this allows cleaning the already printed data, then reloads an error page. Otherwise, we will see half a page of the
contentand an error message. - HTTP requires all header be sent before any body data. Using an output buffer allows us to send a header at any time, because the body data is buffered and hasn't been sent.
- Measure the
Content-Lengthheader. This is required to make the requestcomputablein JavaScript XML API.
At the cost of:
- Output must be buffered in RAM, which increases the memory usage.
When I designed the Bearweb CMS, I decided:
Resource content should be directly output, without any future manipulation, to reduce server load. For example, it should hold the HTML code of a webpage, not a markdown to generate that webpage.
That means, when it is ready to send the content:
- The
contentcan be dumped to the client-side. - As long as the
contentcan be read, there can not be any chance of error occurring.
Therefore, it is wise to turn off the output buffer, and directly send the content to the client.
Resource content in RAM (Database-Backed)
When we fetch a resource from a database, the result from that query will be copied from the database in disk into PHP’s user-space in RAM. This copy of the resource in RAM includes the resource content, which is a large blob and consumes lots of memory.
PDO provides a way to bind the query result into a stream resource. This allows streaming out the large blob to output, without loading the content into RAM.
However, I decide to not implement this feature, because:
- Theoretically (as my understanding, not tested), until the stream is fully sent to client-side, the DBMS must hold a read lock on the resource. For SQLite, this will lock the entire database in that file. It allows other processes to read, but prevents any write to the database.
- For large blobs, it takes a long time to finish the stream, future increases the time for the writing process. For example, if it takes 10 seconds to send the resource to the client-side, the write process will be blocked for 10 seconds. Furthermore, because there is a process waiting to write the database, no other process can obtain read lock until the write process obtains the write lock and finishes the write.
- For SQLite, the lock applies to the entire database file. Other DBMS may support row lock, but not SQLite.
- For databases-backed resources,
contentis less than 100kB in size. The memory footprint is not significant; but it increases the code complexity, which is not worth the effort.
Resource content in RAM (File-Backed)
When reading a resource content from the file system, using file_get_content() method will load that content into RAM. If no future process is required on that resource, one can use readfile() or fpassthru(), which will dump the file content directly to the output.
Therefore, I will:
- Get file size, send a
Content-Lengthheader. - Disable output buffer; then directly dump the file.
Changes to Bearweb CMS with File Content Dump
Content Size
class Bearweb_Site {
public function getContentLength(): int {
return
is_string(get_mangled_object_vars($this)['content'])
? strlen($this->content)
: $this->__file_size();
}
protected function __file_size(): int {
$file = get_mangled_object_vars($this)['content'];
flock($file, LOCK_SH);
fseek($file, 0, SEEK_END);
$len = ftell($file);
if ($len === false)
throw new BW_DatabaseServerError('Cannot get size for blob file: '.$this->url, 500);
flock($file, LOCK_UN);
return $len;
}
}
header('Content-Length: '.$this->site->getContentLength());
In some cases, we may want to know the size of the resource content.
If the resource is database-backed:
- Instance variable
contentis astringvariable in RAM. getContentLength()returns the variable size in RAM. Note, PHP keeps track of variable size. So,strlen($this->content)cost very less.
If the resource is file-backed:
- Instance variable
contentis aresource(file pointer). getContentLength()measures the file size using the file pointer.
Directly Dump
class Bearweb_Site {
public function dumpContent(int $len = -1, bool $header = false): void {
if (is_string(get_mangled_object_vars($this)['content'])) {
if ($header)
header('Content-Length: '.strlen($this->content));
echo $this->content;
} else {
$this->__file_dump($len, $header);
}
}
protected function __file_dump(int $len = -1, bool $header = false): void {
$file = get_mangled_object_vars($this)['content'];
flock($file, LOCK_SH);
if ($len < 0) {
fseek($file, 0, SEEK_END);
$len = ftell($file);
if ($len === false)
throw new BW_DatabaseServerError('Cannot get size for blob file: '.$this->url, 500);
}
if ($header)
header('Content-Length: '.$len);
rewind($file);
fpassthru($file);
flock($file, LOCK_UN);
}
}
ob_end_clean();
$this->site->dumpContent(-1, true);
ob_start();
To dump the content to output:
- Turn off the output buffer. This allows directly send the output to client-side without using buffer in RAM.
- Optionally send the
Content-Lengthheader. - Dump the file.
- Restrat the output buffer.
Do NOT use __file_size() to get the size for Content-Length header before dump for file-backed resource. The file may be modified after releasing the lock in __file_size() but before obtain the lock in __file_dump().
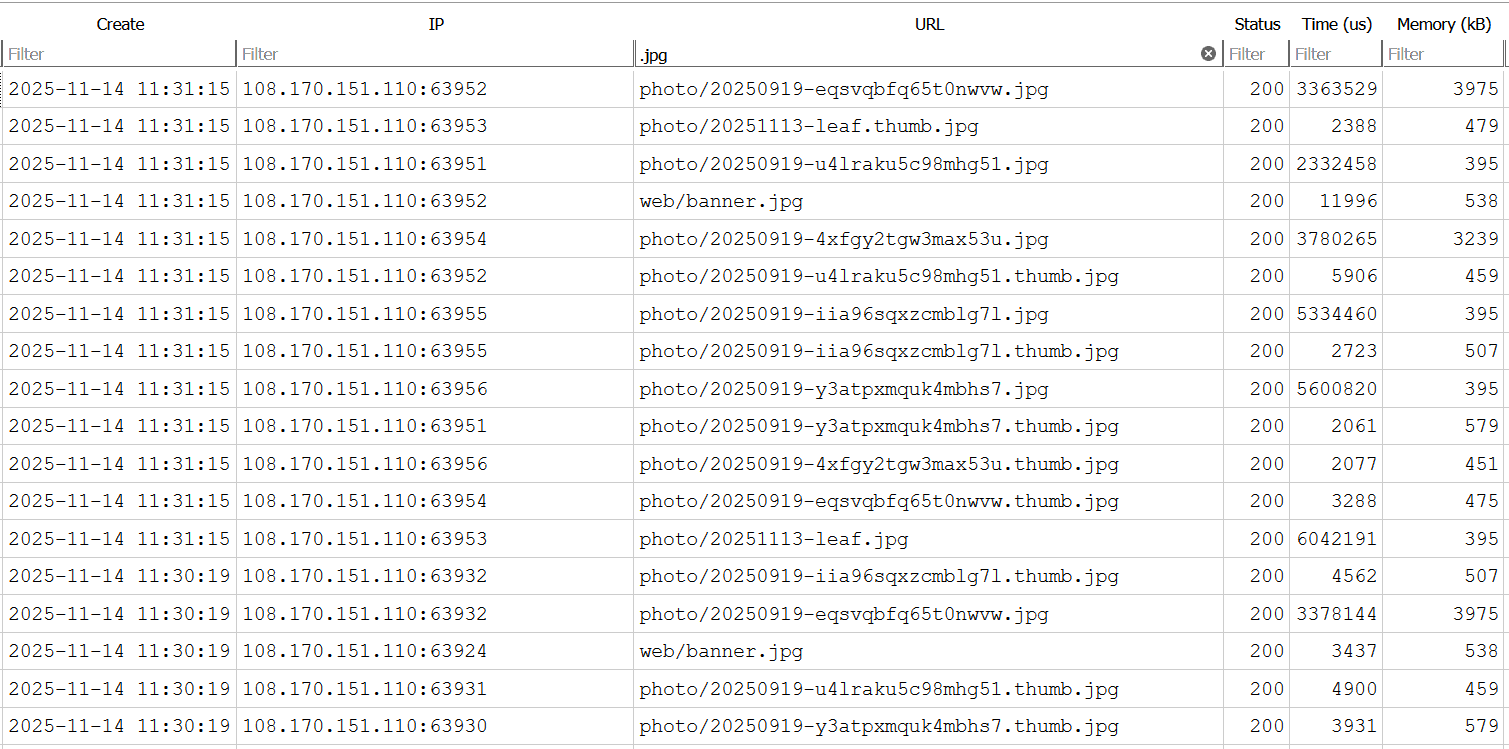
After turnning off output buffer and using direct file dump for large blobs (images), the memory usage dropped significantly.
Now, for the file-backed resources, even the resource file is a few magabytes in size, only 300kB of memory is used. In other words, the reesource content had never been loaded into RAM.
For the database-backed resources, content size ranges from 0 to 100kB. They will use 300kB plus double of the content size, which goes up to 500kB.
Some requests reaches 3MB for unknown reason. However, I am not too concerned. It is less than 10% of the memory limit.