基于ATtiny的WS2812灯条驱动
这篇文章展示了使用AVR单片机(ATtiny)高效驱动WS2812系列LED灯条。算法使用缓存与并行总线的设计来提高系统输出速度与单位时间的数据吞吐量。
WS2812, LED, LED灯条, LED灯带, AVR, ATtiny, 汇编, 分区设计, 并行数据
--by Captdam @ Aug 18, 2025Index
数据格式
LED比特时序
WS2812使用PWM信号来表示0和1比特数据。对于每个比特信号,我们首先需要一定时长的高电平,然后再是低电平。其中,高电平的时长决定了这个信号到底为0(高电平时长较短)还是1(高电平时长较长)。
信号时序
不同厂家不同型号的WS2812要求的时序可能完全不同。不过,大部分情况下,0的高电平基本在0.5微秒以下,1的高电平基本在0.5微秒以上;低电平的时长则并不统一。
下表展现了一些型号的WS2812的时序要求:
| 信号 | 信号0高电平 T0h | 信号0低电平 T0l | 信号1高电平 T1h | 信号1低电平 T1l | 总时长 | 重置 |
|---|---|---|---|---|---|---|
| 时序图 |
|
|
Tnh + Tnl | |||
| XL-6028RGBW-WS2812B | X-250-470 | X-1000-X | 580-850-1000 | X-400-X | 1200-1250-X | 80,000+ |
| XL-5050RGBW-WS2812B-HM | 200-295-350 | 550-595-1200 | 550-595-1200 | 200-295-350 | 900-X-X | 80,000+ |
| XL-3210RGBC-WS2812B | 300-X-X | 900-X-X | 900-X-X | 300-X-X | 1200-X-X | 200,000+ |
| Worldsemi WS2812 | 220-X-380 | 580-X-1000 | 580-X-1000 | 580-X-1000 | N/A | 280,000+ |
| Worldsemi WS2812C-2020-V1/W | 220-X-380 | 580-X-1000 | 580-X-1000 | 580-X-1000 | N/A | 280,000+ |
| Worldsemi WS2812B | 250-400-550 | 700-850-1000 | 650-800-950 | 300-450-600 | 650-1250-1850 | 50,000+ |
可以看出,时序各不相同,比李云龙打平安县时的晋西北还要乱成一锅粥。我们也很难找到一个较为通用的时序,只能对于不同的信号制定不同的策略。更混乱的是,当在网上购买WS2812时,卖家通常只会说这是2812,但是我们没办法知道具体型号。除非我们一买就买一整卷,能看到标签上的厂家和型号信息。只能说,最哈还是实际测量时序,以及不要混用不同厂家不同型号的灯珠(除非我们能测试得出时序兼容)。
8MHz下CPU的输出周期
虽然我们可以使用0到20MHz中的任何一个频率来驱动AVR,一个低成本的系统将使用AVR内部自带的8MHz RC时钟(这样,我们不仅不需要额外的晶振和两个电容,还能额外得到两个IO) 。这样的话,我们的CPU将会以每125纳秒为一个周期。此情况下,输出1和0将需要的CPU周期为:
RC时钟的频率将取决于供电电压与环境温度。我们将需要校准RC时钟以保证输出时序的准确性。特别注意环境温度的变化将导致CPU周期长短变化!在设计时预留一些安全缓冲空间也很重要(比如3个CPU周期为375纳秒,离380纳秒的阈值太近了)。
我们可以微调RC时钟的实际频率来达到时序要求。
| 信号 | 信号0高电平 T0h | 信号0低电平 T0l | 信号1高电平 T1h | 信号1低电平 T1l | 总时长 | 重置 |
|---|---|---|---|---|---|---|
| XL-6028RGBW-WS2812B | X-2-3 | X-8-X | 5-7-8 | X-3-X | 10-10-X | 640+ |
| XL-5050RGBW-WS2812B-HM | 2-2-2 | 5-5-9 | 5-5-9 | 2-2-2 | 8-X-X | 640+ |
| XL-3210RGBC-WS2812B | 3-X-X | 8-X-X | 8-X-X | 3-X-X | 10-X-X | 1600+ |
| Worldsemi WS2812 | 2-X-3 | 5-X-8 | 5-X-8 | 5-X-8 | N/A | 2240+ |
| Worldsemi WS2812C-2020-V1/W | 2-X-3 | 5-X-8 | 5-X-8 | 5-X-8 | N/A | 2240+ |
| Worldsemi WS2812B | 2-3-4 | 6-7-8 | 6-6-7 | 2-3-4 | 6-10-14 | 400+ |
16MHz下CPU的输出周期
如果使用16MHz的晶振来驱动的话(例如Arduino):
一些AVR可以使用内部的PLL来达到更高的频率而不需要依赖外部晶振与时钟输入。
| 信号 | 信号0高电平 T0h | 信号0低电平 T0l | 信号1高电平 T1h | 信号1低电平 T1l | 总时长 | 重置 |
|---|---|---|---|---|---|---|
| XL-6028RGBW-WS2812B | X-4-7 | X-16-X | 10-14-16 | X-6-X | 20-20-X | 1280+ |
| XL-5050RGBW-WS2812B-HM | 4-5-5 | 9-10-19 | 9-10-19 | 4-5-5 | 15-X-X | 1280+ |
| XL-3210RGBC-WS2812B | 5-X-X | 15-X-X | 15-X-X | 5-X-X | 20-X-X | 3200+ |
| Worldsemi WS2812 | 4-X-6 | 10-X-16 | 10-X-16 | 10-X-16 | N/A | 4480+ |
| WorldsemiWS2812C-2020-V1/W | 4-X-6 | 10-X-16 | 10-X-16 | 10-X-16 | N/A | 4480+ |
| Worldsemi WS2812B | 4-6-8 | 12-14-16 | 11-13-15 | 5-7-9 | 11-20-29 | 800+ |
16MHz下CPU的输出周期
如果使用AVR支持的最高频率(20MHz)的外部晶振:
| 信号 | 信号0高电平 T0h | 信号0低电平 T0l | 信号1高电平 T1h | 信号1低电平 T1l | 总时长 | 重置 |
|---|---|---|---|---|---|---|
| XL-6028RGBW-WS2812B | X-5-9 | X-20-X | 12-17-20 | X-8-X | 24-25-X | 1600+ |
| XL-5050RGBW-WS2812B-HM | 4-6-7 | 11-12-24 | 11-12-24 | 4-6-7 | 18-X-X | 1600+ |
| XL-3210RGBC-WS2812B | 6-X-X | 18-X-X | 18-X-X | 6-X-X | 24-X-X | 4000+ |
| Worldsemi WS2812 | 5-X-7 | 12-X-20 | 12-X-20 | 12-X-20 | N/A | 5600+ |
| Worldsemi WS2812C-2020-V1/W | 5-X-7 | 12-X-20 | 12-X-20 | 12-X-20 | N/A | 5600+ |
| Worldsemi WS2812B | 5-8-11 | 14-17-20 | 13-16-19 | 6-9-12 | 13-25-37 | 1000+ |
示例:XL-5050RGBW-WS2812B-HM & Worldsemi WS2812B在不同频率的CPU下面的时序要求
让我们通过XL-5050RGBW-WS2812B-HM和Worldsemi WS2812B在不同频率的CPU下面的时序要求来举例:
| 信号 | 信号0高电平 T0h | 信号0低电平 T0l | 信号1高电平 T1h | 信号1低电平 T1l | 总时长 | 重置 |
|---|---|---|---|---|---|---|
| 时序图 |
|
|
Tnh + Tnl | |||
| XL-5050RGBW-WS2812B-HM | ||||||
| 时序 | 200-295-350 | 550-595-1200 | 550-595-1200 | 200-295-350 | 900-X-X | |
| 8MHz下CPU的输出周期 | 2周期 / 250纳秒 | 6周期 / 750纳秒 | 6周期 / 750纳秒 | 2周期 / 250纳秒 | 8周期 / 1000纳秒 | |
| 16MHz下CPU的输出周期 | 5周期 / 312.5纳秒 | 10周期 / 625纳秒 | 10周期 / 625纳秒 | 5周期 / 312.5纳秒 | 15周期 / 937.5纳秒 | |
| Worldsemi WS2812B | ||||||
| 时序 | 250-400-550 | 700-850-1000 | 650-800-950 | 300-450-600 | 650-1250-1800 | |
| 8MHz下CPU的输出周期 | 3周期 / 375纳秒 | 7周期 / 875纳秒 | 6周期 / 750纳秒 | 4周期 / 500纳秒 | 10周期 / 1250纳秒 | |
| 16MHz下CPU的输出周期 | 6周期 / 375纳秒 | 14周期 / 875纳秒 | 13周期 / 812.5纳秒 | 7周期 / 437.5纳秒 | 20周期 / 1250纳秒 | |
8MHz对于XL-5050RGBW-WS2812B-HM来说太慢了。详情参考下一个章节。
此外,无论是数据0或是数据1都是以高电平开头。在某个时间点(这个例子中的第2个周期时),我们才发送数据(信号0就拉低,信号1就保持拉高)。在另一个时间点(这个例子中的第6个周期时),拉低信号。
显然,在8MHz的情况下,这个时序的要求是很严的。我们将必须把数据缓存到高速的SRAM中,然后再一次性发送出去。
重置
要重置信号流(以从头开始全新的信号流),我们将需要把信号拉低一段不短的时间。上面的例子展示了80微秒或200微秒,不同型号要求不一样,要参考具体型号的时序。
我们可以使用这段时间来在SRAM中准备我们的数据。
此外,我们还可以使用这段时间来操作多条LED链。比如,我们使用100微秒来对LED链A发送数据,使用接下来的1000微秒来对LED链B发送数据。此时,LED链A已完成的重置,我们可以回到LED链A发送下一串数据。
LED字格式
字(Word)代表一个数据单元,其长度取决于应用,而不是固定的16或32比特。
WS2812支持24位RGB色彩。因此,每个LED将会需要24比特的数据来编程。首先是绿色,然后红色,最后蓝色。先发送MSB(高位先发)。
多个LED被串联在一起构成一个链,我们使用一个数据流来控制这个LED链。链中的第一个LED将会消耗最前面24比特信号(比特0到23),第二个LED将会消耗接下来的24比特信号(比特24-47),并以此类推。
八路平行总线
当LED数量增加时,要控制整条链路的LED所需要的时间也会相应增加。
现在,我们只使用了一个输出端口。而AVR(和其他的8位单片机)通常把8个IO集合为一个端口(port)。只操作端口中的单个比特输出对单片机来说是极为低效的。
为了加快传输速度,我们可以将LED链切分为8个分区(Segment)。这样,我们就可以将一个端口的8个IO分别接上一个分区了。
如上图所示,单片机输出的第1个字节将作为八个分区中每个分区的第1个比特,单片机输出的第2个字节将作为八个分区中每个分区的第2个比特,并以此类推……
示例:将24个LED分割为8个分区
下面的例子将展示把24个LED分割为8个分区,每个分区为3个LED。
在分区前,我们想要输出的数据为:
LED 0 G LED 0 R LED 0 B LED 1 G LED 1 R LED 1 B LED 2 G LED 2 R LED 2 B
Segment 0 0000 0000 0000 0001 0000 0010 0000 0100 0000 0101 0000 0110 0000 1000 0000 1001 0000 1010
Segment 1 0001 0000 0001 0001 0001 0010 0001 0100 0001 0101 0001 0110 0001 1000 0001 1001 0001 1010
Segment 2 0010 0000 0010 0001 0010 0010 0010 0100 0010 0101 0010 0110 0010 1000 0010 1001 0010 1010
Segment 3 0011 0000 0011 0001 0011 0010 0011 0100 0011 0101 0011 0110 0011 1000 0011 1001 0011 1010
Segment 4 0100 0000 0100 0001 0100 0010 0100 0100 0100 0101 0100 0110 0100 1000 0100 1001 0100 1010
Segment 5 0101 0000 0101 0001 0101 0010 0101 0100 0101 0101 0101 0110 0101 1000 0101 1001 0101 1010
Segment 6 0110 0000 0110 0001 0110 0010 0110 0100 0110 0101 0110 0110 0110 1000 0110 1001 0110 1010
Segment 7 0111 0000 0111 0001 0111 0010 0111 0100 0111 0101 0111 0110 0111 1000 0111 1001 0111 1010
分区后,我们需要输出:
Addr X0/X8 X1/X9 X2/XA X3/XB X4/XC X5/XD X6/XE X7/XF
0X 0000 0000 0000 1111 0011 0011 0101 0101 0000 0000 0000 0000 0000 0000 0000 0000
0X 0000 0000 0000 1111 0011 0011 0101 0101 0000 0000 0000 0000 0000 0000 1111 1111
1X 0000 0000 0000 1111 0011 0011 0101 0101 0000 0000 0000 0000 1111 1111 0000 0000
1X 0000 0000 0000 1111 0011 0011 0101 0101 0000 0000 1111 1111 0000 0000 0000 0000
2X 0000 0000 0000 1111 0011 0011 0101 0101 0000 0000 1111 1111 0000 0000 1111 1111
2X 0000 0000 0000 1111 0011 0011 0101 0101 0000 0000 1111 1111 1111 1111 0000 0000
3X 0000 0000 0000 1111 0011 0011 0101 0101 1111 1111 0000 0000 0000 0000 0000 0000
3X 0000 0000 0000 1111 0011 0011 0101 0101 1111 1111 0000 0000 0000 0000 1111 1111
4X 0000 0000 0000 1111 0011 0011 0101 0101 1111 1111 0000 0000 1111 1111 0000 0000
因为所有分区的第1个比特合在一起是00000000,所以输出00000000。所有分区的第2个比特合在一起是00001111,所以接下来输出00001111。所有分区的第3个比特合在一起是00110011,所以接下来输出00110011。
竖着看分区前的数据,横着看分区后的数据。
驱动软件
比特驱动
上文中我们讨论到,时序要求非常紧迫,特别是对于XL-5050RGBW-WS2812B-HM,最短的信号要求我们在350纳秒内完成发送,那比8MHz的3个周期(375纳秒)还要短。因此,比特驱动最重要的目标就是快且准。
对于每个比特,我们需要:
- 在最开始,输出高电平。
- 读取当前比特的颜色数据,并前移读指针。
- 在某个时间点,输出颜色数据。
- 在某个时间点,拉低输出电平。
- 检查数据结尾(是否完成所有LED的输出)。
- 如果未完成,回到第一步。
- 如果完成,停止发送并保持拉低一段周期。我们可以趁机准备之后的数据。
下面,我们用C来写一下这个驱动。在这个例子中,我们将使用ATtiny461的PORTA:
1.c
#define SIZE (24 * 8) // 24 bits/LED
#include <avr/io.h>
volatile uint8_t data[SIZE];
void main() {
DDRA = 0xFF;
for (volatile uint8_t* p = data; p < &(data[SIZE]); p++) {
PORTA = 0xFF;
PORTA = *p;
/* asm("nop\n"); */
PORTA = 0x00;
}
for(;;);
}
使用avr-gcc 1.c -o 1.out -mmcu=attiny461 -O3编译。
坏家伙出现了!16位内存总线下的for循环太慢了!
使用avr-objdump -m avr25 -D 1.out > 1.txt来反编译上面的例子:
00000048 <main>:
48: 8f ef ldi r24, 0xFF ; 255
4a: 8a bb out 0x1a, r24 ; 26
4c: e0 e6 ldi r30, 0x60 ; 96
4e: f0 e0 ldi r31, 0x00 ; 0
50: 9f ef ldi r25, 0xFF ; 255
52: 9b bb out 0x1b, r25 ; 27 === Cycle 0 ===
54: 81 91 ld r24, Z+ ; load needs 2 cycles
56: 8b bb out 0x1b, r24 ; 27 === Cycle 3 ===
... nop ; === Cycle 3+n ===
58: 1b ba out 0x1b, r1 ; 27 === Cycle 4+n ===
5a: 81 e0 ldi r24, 0x01 ; 1
5c: e0 32 cpi r30, 0x20 ; 32
5e: f8 07 cpc r31, r24
60: a8 f3 brcs .-16 ; 0x52 <main+0xa> === Cycle 8+n, plus another 2 cycles to jump to beginning of the loop ===
62: ff cf rjmp .-2 ; 0x68 <main+0x20>
问题:
- 在一开始拉高后,需要3个周期才能输出数据。这使得使用8MHz的CPU来操控XL-5050RGBW-WS2812B-HM变得不现实,但是Worldsemi WS2812B战且OK。
- 在最后拉低后,需要5个周期才能完成数据结尾检查并跳转循环的最开始。我们在
for循环中检测指针是否达到数据结尾p < &(data[SIZE]),但因为内存地址是16位宽,所以AVR将需要多个周期来执行计算。
等等……我们是不是可以,比如说:重新排列一下指令来达到时序要求?比如把检测指针的操作放在nop的地方。
驱动就要跑得快
这就轮到汇编上场了:
2.c
#define SIZE (24 * 8) // 24 bits/LED
#include <avr/io.h>
uint8_t data[SIZE];
__attribute__((naked)) void burst(uint8_t* start, uint8_t* end) {
asm(
"movw r30, r24\n\t" // First argument in r25:r24, r31:r30 (Z) are call-used regs
"ldi r24, 0xFF\n\t" // R24 is call-used, content in R24 copied to R30 and no loinger required
// Loop starts
"1: \n\t"
"out %[port], r24\n\t" // Cycle 0
"ld r25, Z+\n\t" // R25 is call-used (load requires 2 cycles)
"out %[port], r25\n\t" // Cycle 3
"cp r30, r22\n\t" // Second argument in r23:r22
"cpc r31, r23\n\t"
"out %[port], r1\n\t" // Cycle 6, R1 is always 0, OUT instruction will NOT clob zero flag
"nop \n\t"
"nop \n\t"
"brne 1b\n\t" // Cycle 9 and 10 (branch requires 2 cycles)
"ret \n\t"
:
: [port] "I" (_SFR_IO_ADDR(PORTA))
);
}
void main() {
DDRA = 0xFF;
burst(data, &(data[SIZE]));
for(;;);
}
使用avr-gcc 2.c -o 2.out -mmcu=attiny461 -O3编译。
再使用avr-objdump -m avr25 -D 2.out > 2.txt反编译:
00000048 <burst>:
48: fc 01 movw r30, r24
4a: 8f ef ldi r24, 0xFF ; 255
4c: 8b bb out 0x1b, r24 ; 27
4e: 91 91 ld r25, Z+
50: 9b bb out 0x1b, r25 ; 27
52: e6 17 cp r30, r22
54: f7 07 cpc r31, r23
56: 00 00 nop
58: 00 00 nop
5a: 1b ba out 0x1b, r1 ; 27
5c: c1 f3 brne .-18 ; 0x4c <burst+0x4>
5e: 08 95 ret
00000060 <main>:
60: 8f ef ldi r24, 0xFF ; 255
62: 8a bb out 0x1a, r24 ; 26
64: 60 e2 ldi r22, 0x20 ; 32
66: 71 e0 ldi r23, 0x01 ; 1
68: 80 e6 ldi r24, 0x60 ; 96
6a: 90 e0 ldi r25, 0x00 ; 0
6c: ee df rcall .-38 ; 0x48 <burst>
6e: ff cf rjmp .-2 ; 0x6e <main+0xe>
成功达成时序要求!
这个驱动遵守AVR-GCC calling convention,只对AVR-GCC ABI兼容!
字格式转换
因为使用平行的数据输出设计,我们将需要对原始的GRB8进行一点格式转换的处理才能使用。
下面的C程序将完成这个格式转换的目标:
#include <stdio.h>
#include <stdint.h>
#include <stdlib.h>
#include <errno.h>
typedef struct __attribute__((packed)) RGB {
uint8_t r, g, b;
} RGB;
typedef struct __attribute__((packed)) Lane {
uint8_t g[8];
uint8_t r[8];
uint8_t b[8];
} Lane;
int main(int argc, char* argv[]) {
if (argc != 7) {
fprintf(stderr, "Use: this leds segments lines frames source dest, (%d given)\n", argc);
return 1;
}
int led = atoi(argv[1]);
int segment = atoi(argv[2]);
int line = atoi(argv[3]);
int frame = atoi(argv[4]);
fprintf(stderr, "%d LEDs per segment, %d segments, %d bits buffer, %d lines, %d frames\n", led, segment, led * segment * 24, line, frame);
uint8_t* bin = malloc(led * segment * 3);
uint8_t* bout = malloc(led * segment * 3);
FILE* fin = fopen(argv[5], "rb");
FILE* fout = fopen(argv[6], "wb");
int pRead[segment]; // Offset in bit (not byte)
int pWrite;
for (int iframe = 0; iframe < frame; iframe++) {
for (int iline = 0; iline < line; iline++) {
pWrite = 0;
for (int isegment = 0; isegment < segment; isegment++) {
pRead[isegment] = isegment * led * 24; // Each segment has 24 * led bits
}
fread(bin, 3, led * segment, fin);
for (int iled = 0; iled < led; iled++) {
for (int ibit = 0; ibit < 24; ibit++) {
for (int isegment = 0; isegment < segment; isegment++) {
int readIdx = pRead[isegment] >> 3;
int readBit = 7 - (pRead[isegment] & 0b111);
uint8_t x = ( bin[readIdx] >> readBit ) & 1;
pRead[isegment]++;
//fprintf(stderr, "Read %d: Byte %d, bit %d: %d\n", ibit, readIdx, readBit, x);
int writeIdx = pWrite >> 3;
int writeBit = 7 - (pWrite & 0b111);
uint8_t write = bout[writeIdx];
write &= ~(1<<writeBit);
write |= x << writeBit;
bout[writeIdx] = write;
pWrite++;
}
}
}
fwrite(bout, 3, led * segment, fout);
for (int i = 0; i < 3 * led * segment; i++) {
fprintf(stderr, "Write %d:\t", i);
for (int j = 7; j >= 0; j--) {
fprintf(stderr, "%c", '0' + ((bout[i] >> j) & 1));
}
fprintf(stderr, "\n");
if (i % 8 == 0b111) fprintf(stderr, "\n");
}
}
}
free(bin);
free(bout);
fclose(fin);
fclose(fout);
return 0;
}
使用gcc -O3 image.c -o image编译。
假设有24个LED分割为8个分区,每个分区为3个LED,原始数据在文件test.in中。我们可以使用命令:./image 3 8 1 1 test.in test.out。生成的处理后的数据将保存在文件test.out中。
下面截图展示了转码前后的数据:

我们应该在电脑上预处理数据。使用单片机实时处理将会很慢。
硬件选择
ATtiny系列单片机选择
为了追求最高效率,我们需要找到一款至少有一个完整8位IO端口的单片机。
根据我的另一篇博客,我们有如下选项:
- ATtint25只有5个IO。
- ATtiny24(或ATtiny441)有2个端口共12个IO,8个在port A,4个在port B。这个选项可用,但是剩下个IO功能有限(特别是port A兼顾了通讯功能)。
- ATtiny261是个好主意。我们可以用port A来驱动LED,用port B来做其他功能(例如通过USI收发数据)。
- ATtiny2313是个好主意。我们可以用port B来驱动LED,用port A和D来做其他功能(例如通过USART收发数据)。
内存大小选择
为了达到时序要求,我们需要在发送数据前,将数据首先缓存到内存SRAM中。
因为每个LED需要24比特数据,切我们使用了8个分区。那么,每8个LED就需要24字节的缓存。
因此,理论上来说,ATtiny能支持的最大LED数量为:
| ATtiny信号 | SRAM内存大小(字节) | 最大可支持LED数量 | 所需内存 | 剩余可用内存 |
|---|---|---|---|---|
| 2X | 128 | 40 | 120 | 8 |
| 4X | 256 | 80 | 240 | 16 |
| 8X | 512 | 168 | 504 | 8 |
如果还要更多内存的话,就需要Tmega了。
你可以制作PCB并焊接LED灯珠(如果你很享受焊接SMD的话)。此外,也可以使用现成的灯带贴在铁棍和木棍上,方便又实惠。
这种灯带有不同密度,常见的有每米144灯珠、60灯珠、30灯珠。下表展现了几种内存大小下使用不同密度灯带的长度关系:
| 缓存大小 | 灯珠数量 | 144/m | 60/m | 30/m |
|---|---|---|---|---|
| 120 | 40 | 0.278m | 0.667m | 1.333m |
| 240 | 80 | 0.556m | 1.333m | 2.667m |
| 504 | 160 | 1.167m | 2.8m | 5.6m |
| 1008 | 336 | 2.333m | 5.6m | 11.2m |
| 2040 | 680 | 4.722m | 11.333m | 22.667m |
单元测试
测试电路
现在,我们可以做一个4灯珠的测试单元来验证我们上面的讨论内容。这个测试单元将模拟1分区中前4个LED。下面展示了这个测试单元的电路图与PCB(当然也可以用灯带代替):
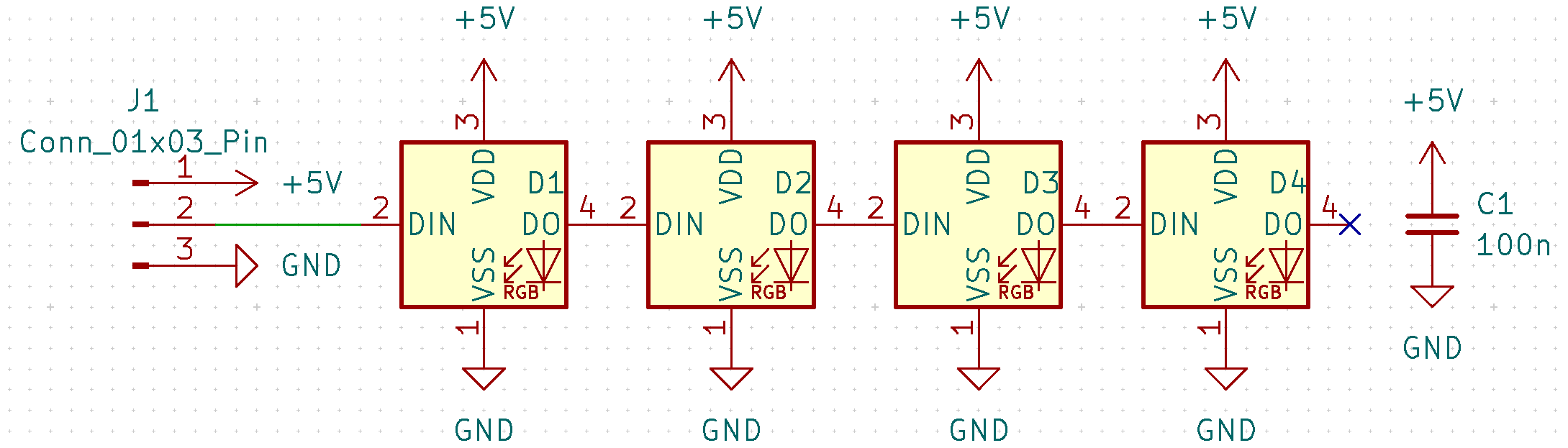
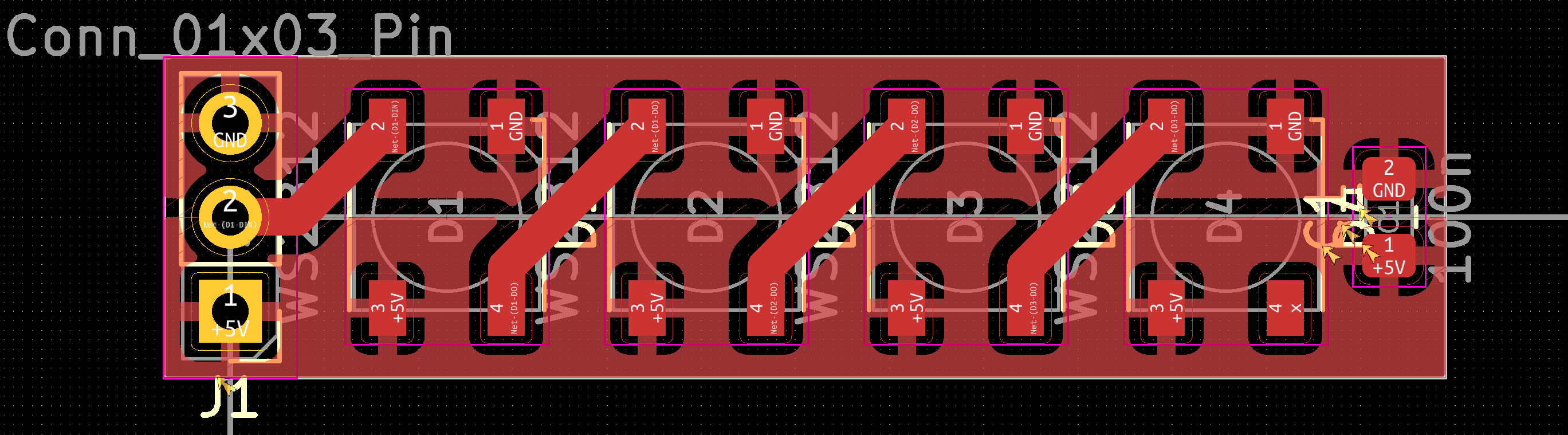
这里是这个测试单元的KiCAD工程文件。
注意信号从左边输入,右边输出。但是,供电在下方,接地在上方。这设计有点违背直觉,我不懂最先设计封装时为什么把供电放下面接地放上面。
我们需要把这个测试单元连接在一块ATtiny44单片机上,并以port A pin 0作为信号端口,以模拟测试分区0。


LED全亮且颜色不同
#define SIZE (24 * 3) // 24 bits/LED, 8 segment, 3LEDs per segment
#include <avr/io.h>
uint8_t data[SIZE] = {
// MSB 7 6 5 4 3 2 1 0 LSB
/* LED 0 */
0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, //Green
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, //Red
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, //Blue
/* LED 1 */
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, //Green
0xFF, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, //Red
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, //Blue
/* LED 2 */
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, //Green
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, //Red
0x55, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, //Blue
/* Parallel design, each bit in a byte represents a segment */
};
__attribute__((naked)) void burst(uint8_t* start, uint8_t* end) {
asm(
"movw r30, r24\n\t" // First argument in r25:r24, r31:r30 (Z) are call-used regs
"ldi r24, 0xFF\n\t" // R24 is call-used, content in R24 copied to R30 and no loinger required
// Loop starts
"1: \n\t"
"out %[port], r24\n\t" // Cycle 0
"ld r25, Z+\n\t" // R25 is call-used
"out %[port], r25\n\t" // Cycle 3
"cp r30, r22\n\t" // Second argument in r23:r22
"cpc r31, r23\n\t"
"out %[port], r1\n\t" // Cycle 6, R1 is always 0, OUT instruction will not clob zero flag
"nop \n\t"
"brne 1b\n\t" // Cycle 7 and 8
"ret \n\t"
:
: [port] "I" (_SFR_IO_ADDR(PORTA))
);
}
int main() {
DDRA = 0xFF;
PORTA = 0x00;
for (uint8_t d = 0; ; d++) {
burst(data, &(data[SIZE]));
for (uint32_t i = 0; i < 100000; i++); // Reset
}
return 0;
}
在上面的例子中,我们将驱动8个分区共24个LED(即每个分区3个LED)。我们将颜色数据保存在数列data[SIZE]中。
/* LED 0 */
0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, //Green
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, //Red
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, //Blue
最前面24字节将会驱动各个分区中第1个LED。
示例中,单片机将会对每个分区都输出11111111 00000000 00000000,这就会将绿色全功率打开。
/* LED 1 */
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, //Green
0xFF, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, //Red
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, //Blue
接下来的24字节将会驱动各个分区中第2个LED。
示例中,单片机将会对每个分区都输出00000000 10000000 00000000,这就会将红色半功率打开。
/* LED 2 */
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, //Green
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, //Red
0x55, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, //Blue
再然后的24字节将会驱动各个分区中第3个LED。
我们要分比特地来看这个例子。因为蓝色地第一个字节是0x55(0b01010101),因此单片机会输出00000000 00000000 10000000到分区0、2、4、6,输出00000000 00000000 00000000到分区1、3、5、7。这就会将分区0、2、4、6的蓝色半功率打开,但是将分区1、3、5、7的蓝色关闭。
因为只输出了72比特到每个分区,且每个LED消耗24比特数据。所以,各分区第三个LED之后的LED将不会得到任何数据。

把程序烧录进单片机。可以看到第一个LED全功率发出绿色,第二个与第三个LED分别半功率发出红色与蓝色。
单片机时钟频率为8MHz,使用avrdude -P com3 -c arduino -p t44 -U lfuse:w:0xa2:m来设置ATtiny44的low fuse来使用内置8MHz RC时钟。
闪烁LED
int main() {
DDRA = 0xFF;
PORTA = 0x00;
for (uint8_t d = 0; ; d++) {
data[0] = ~data[0];
burst(data, &(data[SIZE]));
for (uint32_t i = 0; i < 100000; i++); // Reset
data[32] = ~data[32];
burst(data, &(data[SIZE]));
for (uint32_t i = 0; i < 100000; i++); // Reset
data[64] = ~data[64];
burst(data, &(data[SIZE]));
for (uint32_t i = 0; i < 100000; i++); // Reset
}
return 0;
}
之这个例子中,单片机将分别对LED 0的绿色的最高位、LED 1的红色的最高位和LED 2的蓝色的最高位进行比特反转。这将会导致LED的亮度按照下表模式变化:
| 时间 | LED 0 | LED 1 | LED 2 | 注释 |
|---|---|---|---|---|
| 起始 | 11111111-00000000-00000000 | 00000000-10000000-00000000 | 00000000-00000000-10000000 | 原始数据 |
| 6n+1 | 01111111-00000000-00000000 | 00000000-10000000-00000000 | 00000000-00000000-10000000 | LED 0半功率 |
| 6n+2 | 01111111-00000000-00000000 | 00000000-00000000-00000000 | 00000000-00000000-10000000 | LED 1关闭 |
| 6n+3 | 01111111-00000000-00000000 | 00000000-00000000-00000000 | 00000000-00000000-00000000 | LED 2关闭 |
| 6n+4 | 11111111-00000000-00000000 | 00000000-00000000-00000000 | 00000000-00000000-00000000 | LED 0全功率 |
| 6n+5 | 11111111-00000000-00000000 | 00000000-10000000-00000000 | 00000000-00000000-00000000 | LED 1半功率 |
| 6n+6 | 11111111-00000000-00000000 | 00000000-10000000-00000000 | 00000000-00000000-10000000 | LED 2半功率 |
下面,对单片机编程。
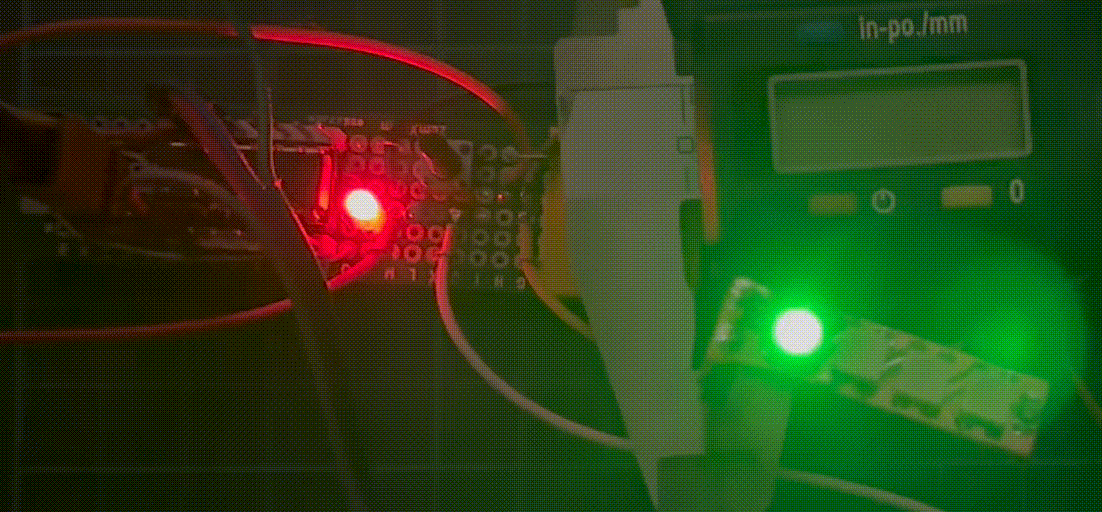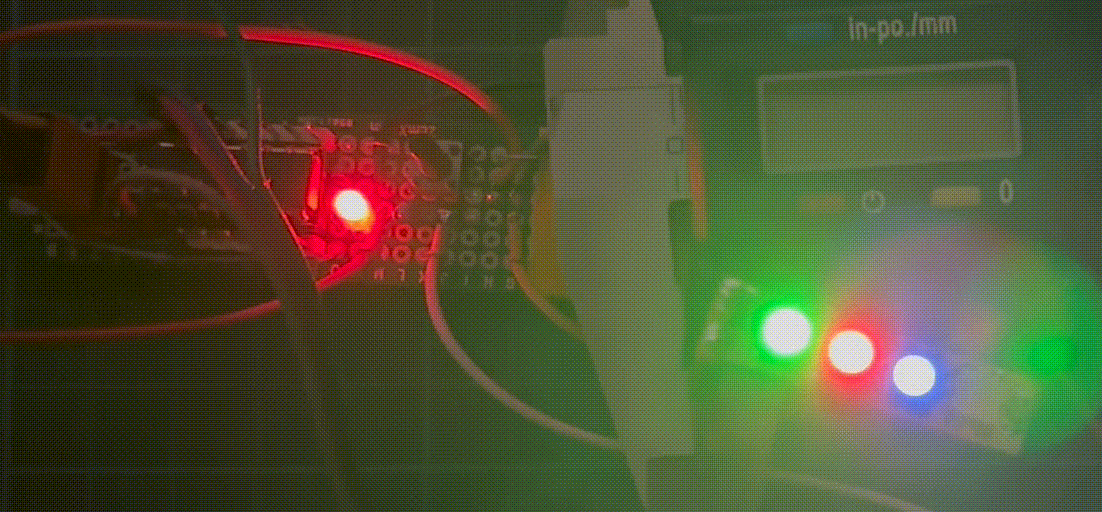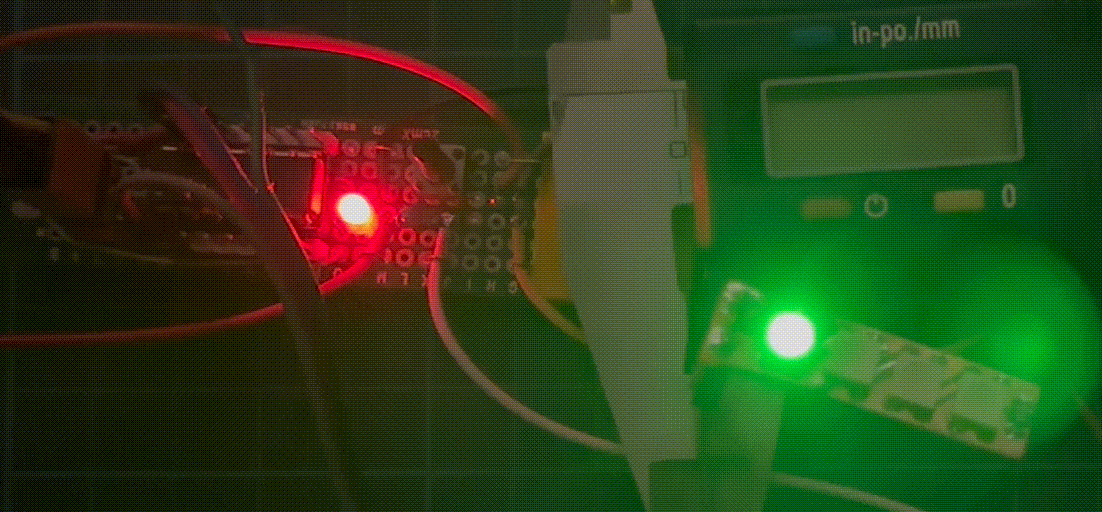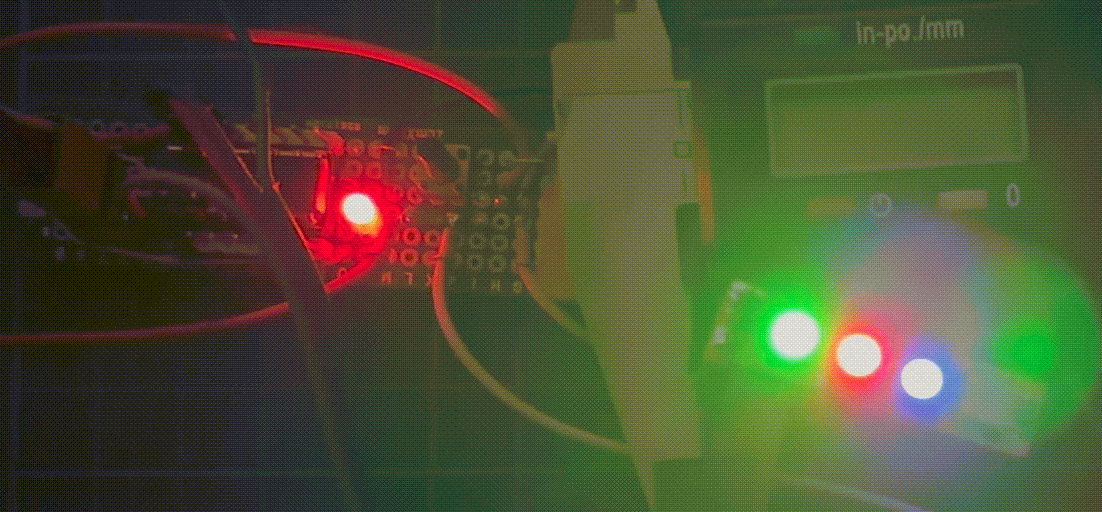
可以看到,LED根据上表的模式闪烁着。注意绿色LED的强度变化。
多段
下面,我们将使用逻辑分析仪来同时检测多个分段的输出。
首先,假设我们的数据储存在EEPROM中。因此,程序中第一步就是将数据从EEPROM中读到SRAM中:
int main() {
DDRA = 0xFF;
PORTA = 0x00;
for (uint8_t i = 0; i < SIZE; i++) {
data[i] = eeprom_read_byte(i);
}
for (uint8_t d = 0; ; d++) {
burst(data, &(data[SIZE]));
for (uint32_t i = 0; i < 100000; i++); // Reset
}
return 0;
}
在烧录程序到单片机时我们还需要将测试数据也烧进EEPROM中:
avr-gcc 3.c -o 3.out -mmcu=attiny44 -O3
avrdude -p t44 -P COM3 -c arduino -U flash:w:3.out -U eeprom:w:image/test.out:r
上电并连接逻辑分析仪,我们可以得到:
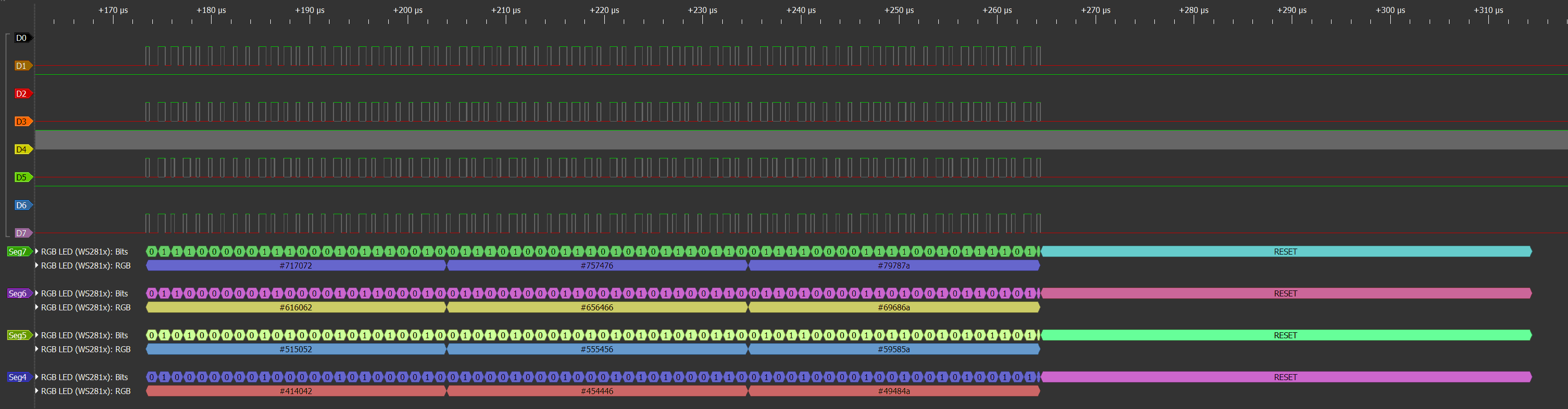
在之前的章节中,我们将下面左边的数据(原始数据)转化为了右边的数据(编码数据):
我们忘EEPROM中烧录了右边的数据(转码数据),我们通过逻辑分析仪测量到的数据和左边的数据(原始数据)一样。