Bearweb内存优化
PHP optimization on the Bearweb CMS to reduce memory usage and chance of OOM.
Bearweb, PHP, 内存占用, 内存优化, 文件大小, OOM, 内存不足, 输出缓冲, 内存, 流
--by Captdam @ Feb 2, 2026Index
资源大小
一个资源代表了网站上的一块信息。一个资源可以是一串构成网页的HTML代码、一个图片或视频文件、一串控制前端特性的JavaScript或CSS代码。资源通过URL来区分。当用户在浏览器地址栏里输入一段特定URL,浏览器就去将该URL代表的资源从服务器下载到客户端并显示之。如果这个资源是HTML、CSS或JavaScript代码的话,浏览器将会解析它,并根据它的内容只是下载更多资源。
衡量一个资源的重要指表之一即该资源的大小。大的资源可以包含更多或是更优质的信息数据,但是需要消耗更大的服务器储存空间,也需要更大的下载带宽。作为网站管理员,我必须要问自己:
- 我将会给一个资源多少储存空间?
- 我将会为访客支付多少下载流量?
- 访客有多少耐心等待一个资源被下载?
HTML网页
我们使用HTML来编写一个网页,并将HTML代码保存在.html文件中。这个文件包含了一个网页的文字信息和结构。此外,还有其它诸如CSS与JS的链接等信息,但这些信息通常来说只占用少量空间。
大部分HTML文件只有几千字节,就算是一些很极端的情况,也不过几十万字节。这个空间足够储存一篇中篇小说了。要阅读这样大小的一个网页会消耗一个普通人半个小时的时间。例如,Wikipedia上关于HTML的词条需要花费约一小时阅读,该网页的大小约为90kB。但是,储存这么多信息只会消耗几乎可以忽略不计的硬盘空间,下载这么多信息对于如今的网络带宽来说也是眨眼之间。
因此,我并不担心HTML文件。
多媒体
图片与视频等多媒体文件则是另一个故事。它们很大,下载很慢。
图表与图纸
图表与(工程)图纸可以被轻易压缩,因为它们包含的信息有限。
方法之一是使用SVG图像格式。它记录了如何绘制一幅图,而不是每个像素点的颜色。因此,一副SVG图像可以有很高的分辨率,但却有很小的文件大小。
另一个方法是使用索引PNG。它使用一张内部的索引表来记录像素点的颜色。对于大量留白、颜色有限的图像(低信息密度)来说,使用索引PNG可以大幅缩减文件大小。
对于图表与图纸,我将首选使用SVG或PNG。它们使用更少的储存空间、更少的网络带宽,也能更快地被访客下载。


上面的例子展示了颜色索引可以将同一张图像的的文件大小压缩到一半。这个过程可能会损失一些颜色,但是这对于图表与图纸来说无伤大雅。你可以点击这些图片来查看细节。


上面的例子展示了使用JPEG保存同一张图像。高质量图看着还行(实际上也有一点模糊了),但是文件很大。低质量图虽然文件小,但是看着很差。你可以点击这些图片来查看细节。
照片
和图表与图纸不同,照片中每个像素都包含了一些信息。最好的压缩方式是使用降低的质量的JPEG格式,这将减少每个像素可以包含的信息量。
使用SVG或PNG是不推荐的。
我的经验与看法是,一张出色的照片(确实是字面意义的出色了)需要保证90%以上的质量,一张不错的照片需要至少70%,一张还行的照片需要30%到40%以上。在某些情况下,如果颜色不太重要,质量再低一点也还尚且可以接受。
当放大一张低质量图片,你将会注意到颜色非常不准确,且8*8的编码区块之间颜色明显断层。

上图展示了一张Cosplay的“原图”PNG文件。下面将展示同一张图片在不同图像质量设置下的JPEG图像:


使用90%质量的JPEG文件将文件相较PNG大小缩减了85%。使用70%质量JPEG进一步将文件大小再缩减了一半。
可以看到,图像文件质量极大地缩减了文件大小,但仅有微乎其微的视觉差别。
使用GIMP导出图像位JPEG文件时可以进一步优化图像。平滑处理可以降低文件大小并减少颜色断层。使用4:2:0再采样可以进一步降低文件大小,但是会牺牲颜色准确度。


上面的例子展示了使用低质量JPEG并再采样保存同一张图像。取决于具体应用,结果可能时可以接受的,也可能时完全不能接受的。特别注意图像中高低频混合的区域,如手指。
视频
还是让油管来支付储存空间和下载带宽吧。
使用文件而不是数据库来保存大的二进制数据(BLOB)
数据库驱动CMS
我是用一个自己搓的Bearweb CMS(内容管理系统)来支持我的网站(也就是这个网站)。Bearweb CMS是数据库驱动的。我使用的DBMS数据库是SQLite。
Bearweb将每一个资源都保存在一张关联结构的表中,即sitemap。每一行都表示一个资源,包含作为PK(主键)的资源url(例如:dir/to/resource.html)。在每一行内,还有资源的各种元数据,例如创建时间、最后修改时间,以及该资源的内容content。
最早,我设计我的网站用来展示我的开发成果。我只会偶尔添加一些图片来作为补充说明,例如工程图、流程图。这些图片都非常小。
其中一些图片可以使用SVG来保存,只会占用几千字节。另外一些可以使用索引PNG,大概只占用10到50kB。
随着我向我的博客增添更多文章,数据库的体积也随之水涨船高。但这也还不是太坏,即使有上百张图片,数据库的大小也还尚可管理。例如:
50kB * 500 images = 25000kB = 25MB
还不错。现在的硬盘都很大,网速也很快。
就算我需要将整个数据库都下载到本地,进行一些修改,再上传回服务器,我的网络带宽也可以在几秒内完成传输。

后来,我决定给每一篇文章都增添海报,例如PCB照片。这些照片类型的图片只能使用JPEG编码。
一张40%质量,2K分辨率的JPEG文件大概在50kB到200kB的大小(就如前面的例子中,一张40%质量420再采样JPEG格式的Cosplay照片:2000 x 1417分辨率24位RGB色彩:127kB)。实际上,40%的质量算是比较差的了,至少得加到70%才能获得不错的照片效果。
不过,对我来说,这些图片仅仅作为美观作用,照片质量差一点也无所谓。但是,就算是我牺牲照片质量以换取储存空间上的节约,将这么多图片(和其它多媒体资源)放入数据库还是会使得数据库过于臃肿。
最近,我开始帮助一个摄影佬朋友搭建博客。对于他来说,图片质量尤为重要。他的图片基本都在8K分辨率以上,且需要很高的图片质量。
也就是说,图片大小轻松起飞上10MB。
大部分他的照片都在20MB到35MB的大小,如果使用PNG格式的话。
如果都保存在数据库的话,维护起来简直地狱。
数据库vs文件系统
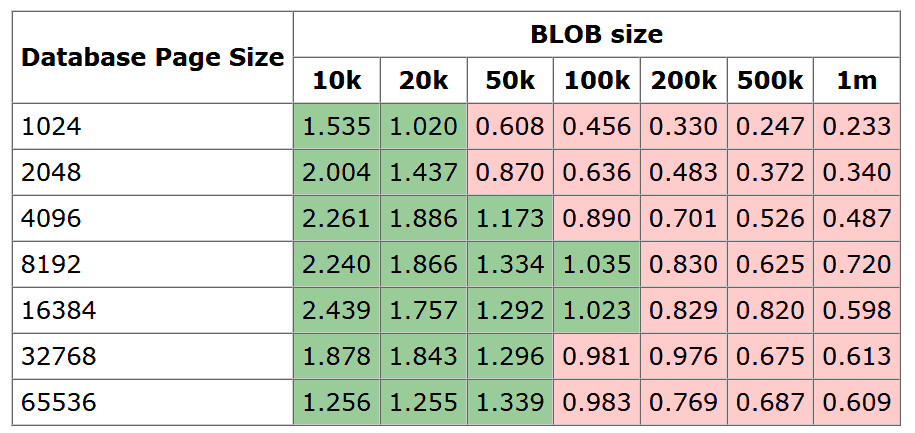
SQLite官方文档Internal Versus External BLOBs in SQLite 也推荐将大的数据(超过100kB)储存在文件系统中而不是数据库中。
虽然实际性能取决于底层系统,我决定采用推荐的100kB作为分界线。对我来说,使用文件系统相较数据库的读取速度性能上的提高并不是重点,而是维护时我是否能方便地下载与上传数据库文件。
我也需要问自己,相较于文件系统,将数据储只存在数据库有什么优点?
- 少打开一次文件。只需要打开数据库文件就可以读取元数据与
content,而不是先打开数据库读取元数据,然后再额外访问文件系统读取content。 - 可以压缩多个小文件。对于文件系统,每一个文件至少占用最小储存空间。对于小资源来说很有用
- 允许全站的
content搜索。对于文字资源来说很有用
大的二进制数据需要这些优点吗?
不!
所以说,我需要使用文件而不是数据库来保存大的二进制数据(BLOB)。
我会称一个资源数据库支持资源(database-backed)或文件支持资源(file-backed),取决于:
| 特性 | 数据库支持 | 文件支持 |
|---|---|---|
| 大小 | 小于分界线(100kB) | 大于或等于分界线(100kB) |
content保存在 |
数据库 | 文件系统 |
数据库中content项目 |
(二进制)字符串string为内容的数据 |
null |
扁平vs结构化文件系统
假设我们有一篇文章的URL是/article/bear。在这篇文章中,我们插入了一张URL为/article/bear/photo.jpg的图片。
在关系数据表中(例如SQLite和MySQL等),所有的资源(数据表行)都是扁平化储存的。也就是说,文章/article/bear和图片/article/bear/photo.jpg可以同时存在。
但是,在文件系统中,文件被结构化地储存。要保存图片/article/bear/photo.jpg,先需要建立文件夹/article/bear,才能在这个文件夹中保存图片/article/bear/photo.jpg。这时,因为文件夹/article/bear已经存在了,就不能用相同的路径名来储存文章/article/bear。
如果我们先保存文章/article/bear为一个文件。当我们需要保存图片/article/bear/photo.jpg时,就无法创建文件夹/article/bear,因为这个路径名已经被用作一个文件了。
我们可以这么理解文件系统。在一个文件夹内,文件可以被读、写、执行。子文件夹就是一个可以被执行的特殊文件。执行这个文件就会向展示这个子文件夹的内容。
/(斜杠)常见于URL中。文件系统使用这个字符来创建文件结构。对于文件系统来说,使用结构化的文件系统是有益的,这能够将庞大的文件系统切分为多个层级。如果使用扁平化的文件系统,访问一个文件则需要查询一张巨大无比的文件列表。而是用结构化的文件系统的话,访问一个文件需要逐级查询每一层的很小(也就是说很快)的文件列表。
对我们来说,结构化文件系统不仅不便于我们创建一个路径名为其它资源的部分路径名的资源,还使得我们的代码结构更复杂,因为我们需要考虑区分文件和文件夹。
在创建文件时,我们将会使用另一个特殊字符#(井号)来代替URL中的/(斜杠)。对于一个网页来说,#被用来分割URL的文件路径名和锚点,因此,#将不会出现在路径名中。另一方面,基本所有文件系统都支持#作为一个文件名。
class Bearweb_Site {
const Dir_Resource = './resource/';
protected static function __file_path(string $url): string { return static::Dir_Resource.str_replace('/', '#', $url); }
}
把一个结构化的URL变成扁平化URL。
转码后,/article/bear就变成了resource/article#bear,/article/bear/photo.jpg就变成了resource/article#bear#photo.jpg。resource/文件夹内再也没有烦人的子文件夹了,两个资源可以同时存在了。
另一个方法是使用扁平化设计的对象储存。但是,我不想再格外部署一个本地对象储存服务器,或是连接一个外部的。这增添了有一层代码复杂度,而且降低了项目的可移植性。
同时读写数据库和文件系统
当包括content在内的所有信息都保存在数据库内时,读取一个资源只需要简单地select站点数据库,修改一个资源只需要简单地update站点数据库,删除一个资源只需要简单地delete站点数据库。
现在,数据库还在这里。但是,对于大的资源(比如高清大图),只有元数据被保存在数据库,content(大于100kB分界线)则会使用资源url作为文件名保存在文件系统内。
相较于单纯使用select、update、delete来操作数据库读、改、删,并依赖DBMS(数据库管理系统)提供的ACID特性。现在,我们需要使用事务(transaction)管理来保证DMBS和文件系统同时满足ACID特性:
- 原子性(Atomicity):在一个事务中,我们首先修改数据库,但是不要提交。再修改文件系统。如果文件系统修改(写/删)成功,再提交数据库的修改。否则,就回滚数据库。对于使用回滚记录模式的SQLite来说,提交修改只需要删除回滚日记即可。因此,提交数据库修改应该总是成功的,除非是文件修改后但是数据库提交前断电了或者系统崩溃了,这在服务器上不太可能发生。
- 一致性(Consistency):如今的服务器硬件应该没问题。
- 事务隔离(Isolation):数据库的文件系统都使用读写锁。
- 持久性(Durability):如今的服务器硬件应该没问题。
我们认为文件系统的读写应该是要么成功要么失败的。如果一个文件能被以读模式打开,那么就应该没有问题读出所有的content。如果一个文件能被以写模式打开,那么就应该没有问题将所有的content写入硬盘。这里不该有做到一半就失败的案例。
就算系统没能保证上面的特性,当一个用户做出修改后,用户应该检查修改的结果。
修改Bearweb CMS Sitemap数据库
如果保存在数据库中的content是字符串string(数据库支持),该string就是实际的content 数据。如果content是空值null(文件支持),那就说明实际content保存在文件系统中。
对象content变量
class Bearweb_Site {
public string $url;
... // Other metadata
public mixed $content { // resource|string
get => is_string(get_mangled_object_vars($this)['content']) ? $this->content : $this->__file_read(-1);
}
}
资源的content可以是:
- 数据库支持:一串
string包含该资源的实际数据。注意,PHP的string是可以包含二进制数据的。 - 文件支持:一个
resource(PHP文件指针)指向包含实际数据的文件。
PHP不支持把resource作为一个类型,所以我们只能用mixed来代替resource|string作为content的类型。
当使用content时:
- 数据库支持:返回变量
string content内的数据。 - 文件支持:将文件指针
resource content指向的文件的内容读出来并返回。
PHP 8.4引入了property hook来让我们创建对象变量的getter和setter。这里,如果是文件支持的资源,使用getter就可以自动把实际内容从文件读出来。
我们必须使用get_mangled_object_vars($this)['content']来读取对象变量content的原始数据。对于文件支持的资源来说会得到一个resource,对于数据库支持的的资源来说会得到一个string。
使用$this->content将会返回content的hooked(getter)的结果,永远为一个string。即使是文件支持的资源,getter也会自动读取文件系统并返回string对象型的内容。
读
class Bearweb_Site {
public static function query(string $url): ?static {
try {
$sql = static::$db->prepare('SELECT * FROM `Sitemap` WHERE `url` = ?');
$sql->bindValue( 1, $url, PDO::PARAM_STR );
$sql->execute();
$site = $sql->fetch();
$sql->closeCursor();
if (!$site)
return null;
$site['content'] = $site['content'] ?? fopen(static::__file_path($site['url']), 'rb');
return new static(...$site);
} catch (Exception $e) { throw new BW_DatabaseServerError('Cannot read sitemap database: '.$e->getMessage(), 500); }
}
}
要读一个资源:
- 从数据库读取资源。如果读取失败,抛出一个错误。此时不会有文件读取。
- 如果数据库返回的
content是null,那就说明content保存在文件系统中。 - 接下来,以二进制只读模式打开文件。如果打开文件失败,抛出一个错误。从数据库读取的内容会被舍弃。
我们使用只读模式打开文件。这允许我们在文件系统中应用访问控制。例如,我们可以把一张图片设置为Apache(www-data)只可读。这样读取这张图片就可以成功,但是无法修改。
对于文件支持的资源,我们只打开content,只有在需要使用时才会去真正执行读这个操作(lazy-read)。在不需要使用content的情况下,这样做能节约文件系统读的消耗。
插入和修改
class Bearweb_Site {
const Size_FileBlob = 100000;
public function insert(): void { try {
static::$db->beginTransaction();
try {
$sql = static::$db->prepare('INSERT INTO `Sitemap` (`url`, `...`, `content`) VALUES (?, ?, ?)');
$sql->bindValue(1, $this->url, PDO::PARAM_STR );
$sql->bindValue(2, ..., ... );
if (strlen($this->content) >= static::Size_FileBlob) {
$sql->bindValue(3, null, PDO::PARAM_NULL);
} else {
$sql->bindValue(3, $this->content, PDO::PARAM_STR);
}
$sql->execute(); // Not committed yet
if (strlen($this->content) >= static::Size_FileBlob) {
$this->__file_write();
} else {
$this->__file_delete();
}
static::$db->commit();
} catch (Exception $e) {
static::$db->rollBack();
throw $e;
}
$sql->closeCursor();
} catch (Exception $e) { throw new BW_DatabaseServerError('Cannot insert into sitemap database: '.$e->getMessage(), 500); } }
public function update(): void { try {
static::$db->beginTransaction();
try {
$sql = static::$db->prepare('UPDATE `Sitemap` SET `...` = ?, `content` = ? WHERE `URL` = ?');
$sql->bindValue(1, ..., ... );
$sql->bindValue(3, $this->url, PDO::PARAM_STR );
if (strlen($this->content) >= static::Size_FileBlob) {
$sql->bindValue(2, null, PDO::PARAM_NULL);
} else {
$sql->bindValue(2, $this->content, PDO::PARAM_STR);
}
$sql->execute(); // Not committed yet
if (strlen($this->content) >= static::Size_FileBlob) {
$this->__file_write();
} else {
$this->__file_delete();
}
static::$db->commit();
} catch (Exception $e) {
static::$db->rollBack();
throw $e;
}
$sql->closeCursor();
} catch (Exception $e) { throw new BW_DatabaseServerError('Cannot update sitemap database: '.$e->getMessage(), 500); } }
}
要插入或修改一个大的资源(文件支持):
- 开始一个事务。
- 将元数据写入数据库,将
null写入content列。如果数据库写失败,抛出一个错误。数据库没有被提交,文件系统也没有修改。 - 将
content写入文件。如果文件写失败,抛出一个错误。因为数据库修改还未提交,我们可以回滚。 - 提交本事务。
要插入或修改一个小的资源(数据库支持):
- 开始一个事务。
- 将资源写入数据库。如果数据库写失败,抛出一个错误。数据库没有被提交,文件系统也没有修改。
- 删除资源文件(如果存在的话),这是因为这个资源可能之前是文件支持的。如果文件写失败,抛出一个错误。因为数据库修改还未提交,我们可以回滚。
- 提交本事务。
删除
class Bearweb_Site {
public function delete(): void { try {
static::$db->beginTransaction();
try {
$sql = static::$db->prepare('DELETE FROM `Sitemap` WHERE `URL` = ?');
$sql->bindValue(1, $this->url, PDO::PARAM_STR );
$sql->execute(); // Not committed yet
static::__file_delete();
static::$db->commit();
} catch (Exception $e) {
static::$db->rollBack();
throw $e;
}
$sql->closeCursor();
} catch (Exception $e) { throw new BW_DatabaseServerError('Cannot delete blob file from sitemap database: '.$e->getMessage(), 500); } }
}
要删除一个资源:
- 开始一个事务。
- 将数据库中代表这个资源的行删除。如果数据库写失败,抛出一个错误。数据库没有被提交,文件系统也没有修改。
- 删除资源文件(如果存在的话),这是因为这个资源可能之前是文件支持的。如果文件写失败,抛出一个错误。因为数据库修改还未提交,我们可以回滚。
- 提交本事务。
修改Bearweb CMS资源文件系统
接下来,我们需要整合文件系统事务控制与数据库事务控制:
读
class Bearweb_Site {
protected function __file_read(int $len = -1) {
$file = get_mangled_object_vars($this)['content'];
flock($file, LOCK_SH);
if ($len < 0) {
fseek($file, 0, SEEK_END);
$len = ftell($file);
if ($len === false)
throw new BW_DatabaseServerError('Cannot get size for blob file: '.$this->url, 500);
}
rewind($file);
$content = fread($file,$len);
if ($content === false)
throw new BW_DatabaseServerError('Cannot read from blob file: '.$this->url, 500);
flock($file, LOCK_UN);
return $content;
}
}
在读之前,应该先获得共享锁(读锁),以防止在读的过程中文件被修改。PHP将会等待直到获得读锁。如果一定时间内不能获得读锁,当前PHP进程就会超时。这种情况下,将不会有任何读操作。
这会发生在网站非常繁忙(这里指长时间写这个资源,大量的长时间的读无所谓,因为是共享读锁)的情况下,或是代码中出现了互锁(程序员又喝高了),是不太可能发生的。如果真的发生了,Apache会直接返回错误。
获得读锁后,我们就可以从文件中读取len字节长的数据。如果len为负,就先测量文件长度。
最后,解锁以便其它进程能写这个文件。
当不再需要这个文件后就立刻解锁,以便其他进程可以马上获取写锁,缩减等待时间。
当前脚本完成后也会自动解锁。所以,我们可以省略错误发生(其实也没那么容易出错)时手动解锁的过程,来少写一点代码。
写
class Bearweb_Site {
protected function __file_write(): void {
$file = fopen(static::__file_path($this->url), 'wb');
flock($file, LOCK_EX);
rewind($file);
if (fwrite($file, $this->content) === false)
throw new BW_DatabaseServerError('Cannot write to blob file: '.$this->url, 500);
flock($file, LOCK_UN);
fclose($file);
}
}
当需要写一个资源时,对象变量content包含了要写的内容。我们先创建一个写指针fopen(path, 'wb')。
在写之前,应该先获得专用锁(写锁),以防止有其它进程在读写这个文件。PHP将会等待直到获得读锁。如果一定时间内不能获得读锁,当前PHP进程就会超时。这种情况下,将不会有任何写操作。
获得写锁后,我们就可以把content写入文件了。如果文件写失败,抛出一个错误。
最后,解锁以便其它进程能读写这个文件。
删
class Bearweb_Site {
protected function __file_delete(): void {
$path = static::__file_path($this->url);
if (!(is_file($path) ? unlink($path) : true))
throw new BW_DatabaseServerError('Cannot unlink blob file: '.$this->url, 500);
}
}
如果文件存在,就删除。
如果删除失败,抛出一个错误。
Linux手册指出:unlink() deletes a name from the filesystem. If that name was the last link to a file and no processes have the file open, the file is deleted and the space it was using is made available for reuse. If the name was the last link to a file but any processes still have the file open, the file will remain in existence until the last file descriptor referring to it is closed.
unlink()将文件名从文件系统中删除。如果这个文件名指向一个文件,并且该文件没被任何进程打开,那么就删除该文件,并返还储存空间。如果这个文件还被任何进程打开中,文件会被保留,直到最后一个文件指针被关闭。
也就是说,如果我们删除(确切说叫取消文件到文件名的链接)一个文件,文件系统会保留这个文件直到不再被打开。所以,我们不需要特意加锁。当前还在读写这个文件的进程可以继续读写。
内存消耗
一次OOM(内存耗尽)事故
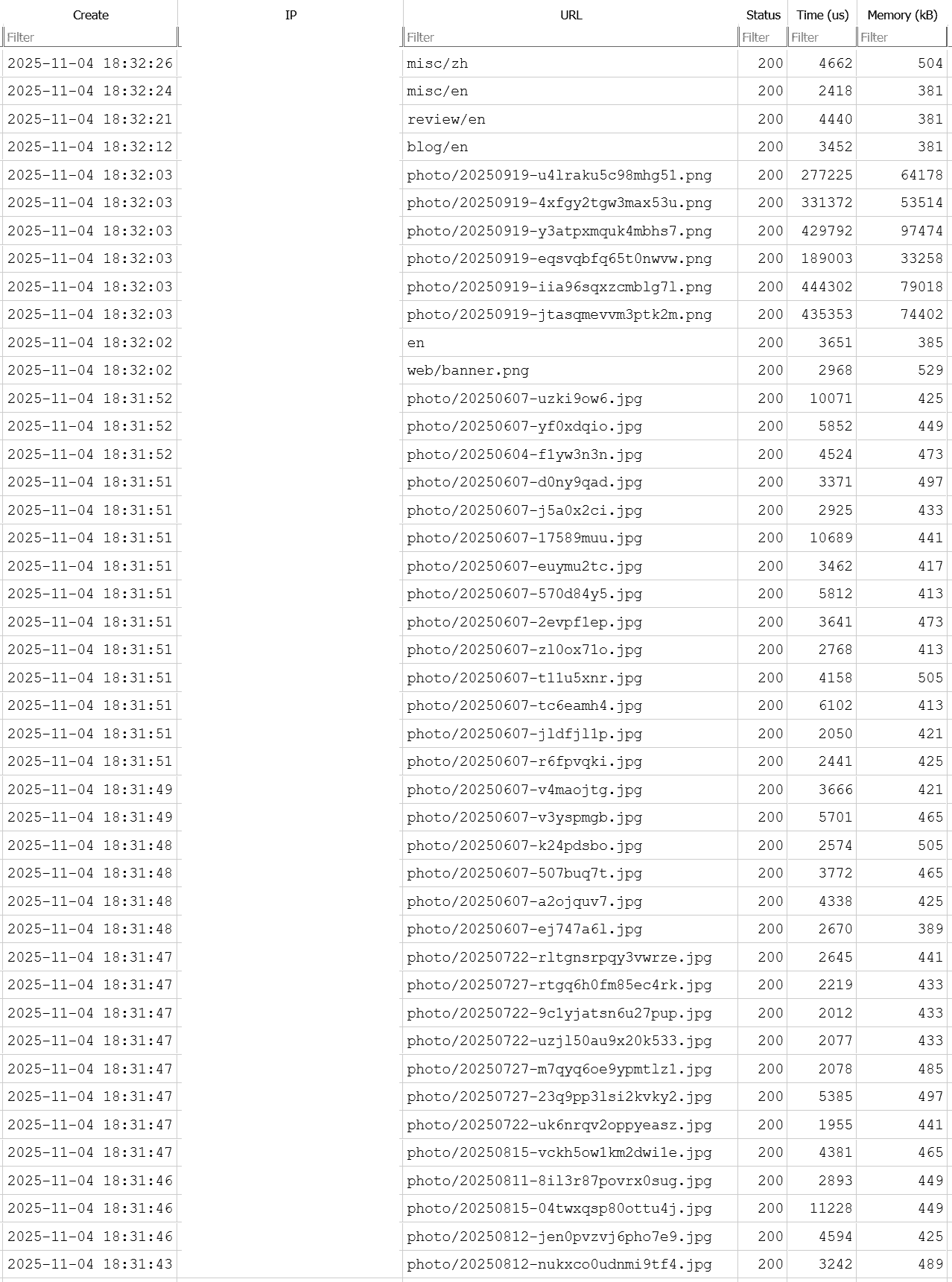
最近一次(也许是DDos)事故导致了我的服务器宕机。检查日志表示,一些HTTP请求了大尺寸的资源导致了服务器内存不足(OOM-killed)。
幸好每次请求的时间消耗和内存消耗我都有记录。
当Bearweb CMS处理一个请求时,其内存消耗主要由3点构成:
- 固定的约300kB。这包括了PHP脚本内的变量和底层Apache、PHP引擎、PHP脚本本身。
- 载入内存的资源的
content。 - 输出缓冲。该缓冲大小和资源大小相等。
举一个例子,假如有一个30MB的PNG图片,将会消耗的内存为:
300kB + 30MB + 30MB = 60.3MB
这也太大了!一个1GB内存的服务器只能同时相应最多15个这样的请求,不然Apache就会因为内存耗尽被系统杀掉。
大多数情况下,我的网站并没有太多访客,也就是说,不太容易出现这么多同时的请求。另外,大部分请求都是很小的资源(比如HTML代页面、JS脚本、小缩略图),就算是大量请求,总内存也不会太大。另一方面,请求的响应速度快,新的请求到达时旧的请求早就处理完发送出去了(内存也就释放了)。因此,总内存消耗并不高。
这次,大量、同时、大尺寸资源的请求导致了内存消耗飙升。
_(:3 _| )__ 搞了约十年web第一次给我干OOM了。
资源大小
最简单的改善方式就是缩小资源大小了。
30MB的高清大图确实看着爽“看,每一根毛孔都看得清清楚楚!”,但是在网站上放这么大的图片确实不太合适。大部分访客基本只会打开就关闭图片。应该没什么人拿着放大镜看屏幕吧。
因此,在网站上放高清大图并不合适。压缩的、质量还OK的图片时更好的选择。我的观点是,10MB是一个比较好的平衡点。
相较于30MB的图片消耗60MB的内存,10MB的图片只消耗20MB内存,不考虑其它优化的话。
进程数量
Apache使用多个进程(worker)来同时响应多个请求。
这次OOM的原因就是太多的同时请求消耗了太多的总内存。
我们可以通过减少最高允许进程数量的方式来限制同时能处理的请求数量。当有大量突发请求时,多余的请求会被放在队列中依次处理。
我对Apache的配置文件mpm_prefork.conf进行了如下修改:
<IfModule mpm_prefork_module>
StartServers 5
MinSpareServers 5
MaxSpareServers 10
MaxRequestWorkers 40
MaxConnectionsPerChild 1000
</IfModule>
因为限制每个请求PHP最多消耗32MB内存,40个请求最多消耗1.2GB内存。这是我的服务器的空闲内存和swap空间的总和。
实际上,大部分的请求都只占用可以忽略不计的内存空间(少于1MB),因此基本所有请求都可以用物理内存处理。只有在极端情况下,大量请求大尺寸资源时,才会有一些请求需要用到swap。虽然swap很慢,但是比OOM爆掉好,可以想象成一个后备内存。
也有观点是使用平均内存消耗来计算最大进程数量。我决定使用最大内存消耗来计算以应对最坏情况。
我还设置MaxConnectionsPerChild为1000来防止内存泄漏。一个进程在处理1000次请求后就会被回收。这个设置并不是必要的,但是我觉得这更安全一点。
输出缓冲
使用输出缓冲带来如下优点:
- 相较于发送多个小的数据片段,一次性发送可以节约发送时间,也就能提高请求处理速度。减少请求处理速度,也就能降低同时处理的请求数量。
- 允许清空缓存并装入新的内容。例如,当错误发生时,可以清除已经输出的数据,然后装入错误页面。不然,我们就会看到半个
content和一条错误信息。 - HTTP要求所有的头(header)都在内容(body)前输出。使用输出缓存允许我们随时输出HTTP头,因为内容被缓存了,还没有被实际发送。
- 测量
Content-Length头。这使得请求在JavaScript XML API中computable。
缺点是:
- 输出缓冲需要占用内存。
当我设计Bearweb CMS时,我决定:
资源内容content应该被直接输出,不需要任何进一步处理,以节约服务器系统占用。比如说,网页资源的内容应该是HTML代码,而不是用于生成HTML代码的的markdonw。
也就是说,当准备发送content时:
content可以被直接输出(dump)。- 只要能读到
content,就不该出任何错。
因此,应该关掉输出缓冲,直接发送content。
资源content内存占用(数据库支持)
当我们从数据库读取一个资源,该查询的结果就会被从硬盘上的数据库内复制到PHP空间的内存中。内存中的资源也包括了content,一个大的二进制数据,占用大量内存空间。
PDO提供了一个方法来把结果作为一个流(stream)。这允许我们以流的方式来输出这个二进制数据,而不用把content读入内存中。
但是,我决定不采用该功能:
- 理论上来说(按照我的理解),直到我们将这个流完全发送,DBMS需要保持在这个资源上设置一个读锁。对于SQLite来说,上锁将会锁住整个整个数据库文件。其他进程虽然可以继续读这个数据库,但是不能修改。
- 对于大的二进制数据,发送这个流也会消耗大量时间,进一步堵塞写操作。举一个例子,如果发送这个资源带客户端消耗10秒,写数据库的进程就需要等待10秒。同时,因为有一个进程在等待写数据库,之后的进程将必须等待写的进程获得写锁并写完。
- SQLite只有文件锁。其它DBMS也许支持行锁,但是SQLite不行。
- 数据库支持的资源
content最大100kB。这对内存占用优化并不高,但是却会大幅提高代码复杂度,得不偿失。
资源content内存占用(文件支持)
当从文件系统中读取一个资源的content时,使用file_get_content()将会把content读入内存。如果不需要进一步处理资源的话,可以使用readfile()或fpassthru()来直接输出。
所以,可以:
- 获取文件大小以发送
Content-Length头。 - 禁用输出缓冲,直接输出文件内容。
修改Bearweb CMS支持直接输出文件内容
内容大小
class Bearweb_Site {
public function getContentLength(): int {
return
is_string(get_mangled_object_vars($this)['content'])
? strlen($this->content)
: $this->__file_size();
}
protected function __file_size(): int {
$file = get_mangled_object_vars($this)['content'];
flock($file, LOCK_SH);
fseek($file, 0, SEEK_END);
$len = ftell($file);
if ($len === false)
throw new BW_DatabaseServerError('Cannot get size for blob file: '.$this->url, 500);
flock($file, LOCK_UN);
return $len;
}
}
header('Content-Length: '.$this->site->getContentLength());
有时,我们想要知道资源content的大小。
如果是数据库支持的资源:
- 对象变量
content是内存中的string。 getContentLength()会返回内存中该变量的大小。因为PHP会追踪每个变量的大小,所以strlen($this->content)没有什么系统消耗。
如果是文件支持的资源:
- 对象变量
content是一个resource(文件指针)。 getContentLength()通过该指针测量文件大小。
直接输出
class Bearweb_Site {
public function dumpContent(int $len = -1, bool $header = false): void {
if (is_string(get_mangled_object_vars($this)['content'])) {
if ($header)
header('Content-Length: '.strlen($this->content));
echo $this->content;
} else {
$this->__file_dump($len, $header);
}
}
protected function __file_dump(int $len = -1, bool $header = false): void {
$file = get_mangled_object_vars($this)['content'];
flock($file, LOCK_SH);
if ($len < 0) {
fseek($file, 0, SEEK_END);
$len = ftell($file);
if ($len === false)
throw new BW_DatabaseServerError('Cannot get size for blob file: '.$this->url, 500);
}
if ($header)
header('Content-Length: '.$len);
rewind($file);
fpassthru($file);
flock($file, LOCK_UN);
}
}
ob_end_clean();
$this->site->dumpContent(-1, true);
ob_start();
要直接输出content:
- 禁用输出缓冲。这将直接输出到客户端,不再使用内存中的缓冲。
- 如果需要,发送
Content-Length头。 - 直接输出文件。
- 重启输出缓冲。
对于文件支持的资源,发送前不要使用__file_size()来手动测量内容大小并发送Content-Length头。因为文件可能在__file_size()后、__file_dump()前被另一个进程修改。
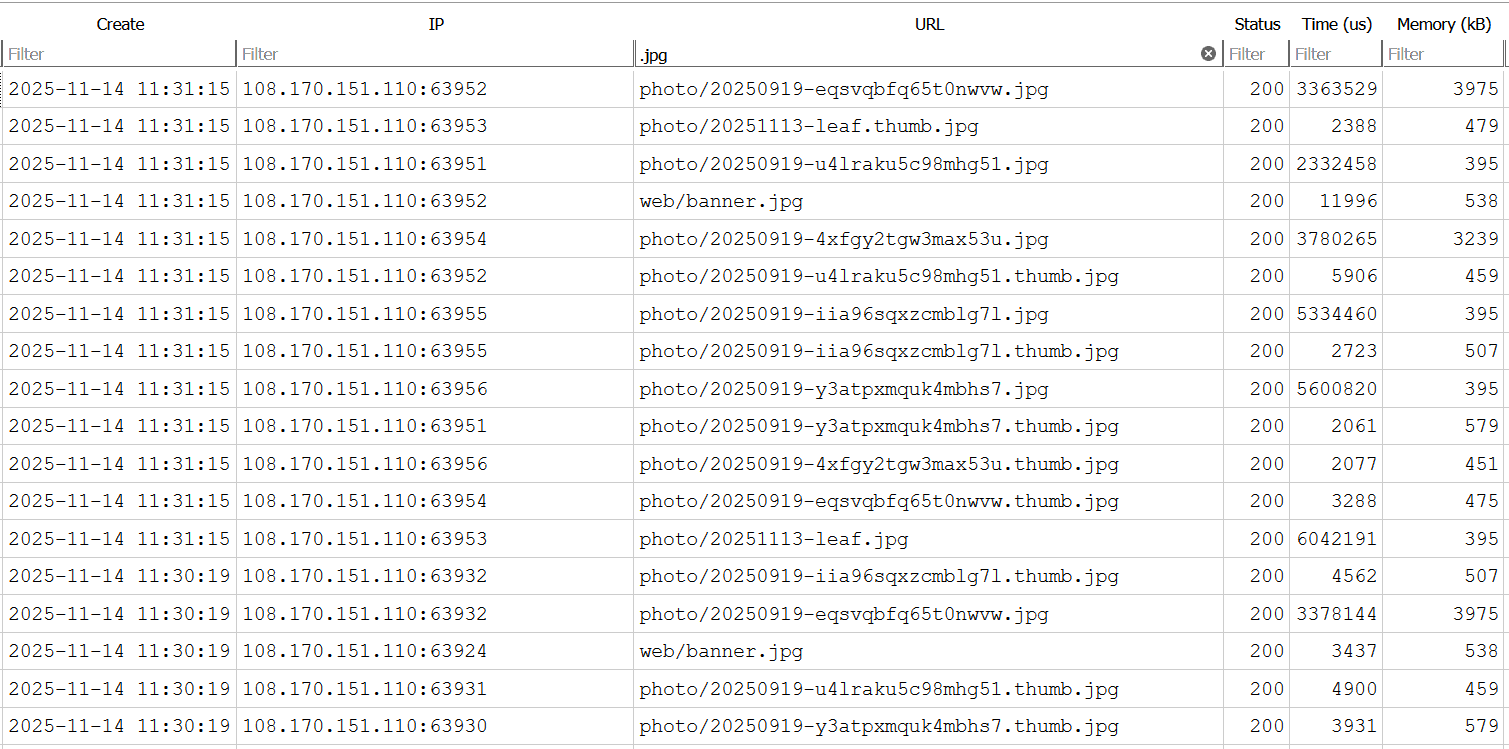
当关闭输出缓冲并直接输出大尺寸二进制的文件(比如图片)后,内存消耗明显改善。
现在,对于文件支持的资源,就算文件有好几MB大,也只会消耗约300kB内存。也就是说,资源的content将不会再被载入内存。
对于数据库支持的资源,content的大小在0到100kB之间。这将消耗300kB加上二倍于content大小的内存,也就最多500kB。
有的请求因为不明原因消耗了3MB内存。不过还不用太担心,这只有内存上限的10%。