AVR调用栈
这篇文章将从底层硬件的角度讨论并展示AVR-GCC在调用子程序时的栈操作。
AVR, GCC, 栈, 调用框架, SP, 栈指针, FP, 框架指针
--by Captdam @ Mar 3, 2025Index
关于栈
如果你并不是很了解计算机硬件架构,CPU将内存看作为一个栈(Stack)。栈是一种越早存入的数据会被越晚取出的存储类型,也叫做FILO。
CPU还有一个指针叫做栈指针(Stack Pointer),简写为SP。栈指针永远指向栈的最顶端,它的作用是在一些特定指令下告诉CPU在哪里进行读写(入栈出栈)。
栈可以是向上生长的,也可以向下生长的,所以入栈操作可以增加SP的值,也可以降低SP的值。AVR的栈向下生长。
栈指针SP可以是指向下一个可写地址的,也就是说,入栈操作会写在SP所指的位置,然后SP才会移动。SP也可以是指向刚写入的地址的,也就是说,入栈操作会先移动SP,然后再写在SP所指的位置。AVR的SP是指向下一个可写地址的。
入栈(push)会将数据写在栈的顶部并移动SP。之后入栈的数据会处在之前入栈的数据的上方。
出栈(Pop)(或者叫Pull)会从栈的顶部读出一个数据并移动SP。之后出栈的数据会在之前出栈的数据的下方。
CPU一般来说有三种内存寻址模式:
- 直接寻址将数据的绝对地址编码在程序指令中,用于地址在编译时就已经知道的数据。
- 间接寻址(寄存器间接寻址)使用寄存器中的值作为数据的地址(有的架构还支持在这个地址的基础上添加一个编码在指令中的位移),用于地址在编译时不知道,而需要在运行时实时进行计算的情况。
- 最后就是栈指针寻址(我暂时还没来呢个找到一个专用的说法),和间接寻址类似,但是限制只能使用SP的值作为数据的的地址。有的架构赋予了栈指针寻址额外的功能,例如入栈/出栈可以自动移动SP指向的地址;另一些架构(比如MIPS)则没有专门的SP,而是通过一般的通用寄存器来模拟SP的功能。
下面是一个演示入栈与出栈操作的小程序。你可以关掉Auto功能并手动Reset/Index来方便观察。
注意:这个机器使用2字节的空间来存储16比特长的PC(程序计数器)。
关于子程序
返回地址(Return Address)
CPU执行程序储存中的指令(二进制码)。CPU通过将PC从主程序的地址修改为子程序的地址的方式来进入一个子程序,并在最后通过将PC修改回主程序的地址的方法来回到主程序。
在架构层面上,CPU使用PC(程序指针)来指向CPU需要执行的指令的地址。当完成一条指令后,PC移动到下一条指令。
当CPU需要执行“跳转到地址为XXX的子程序”的指令时(对AVR来说就是call XXX)CPU将会:
- 将当前PC入栈,此时PC指向了主程序的下一条指令。
- 修改PC为所提到的子程序的地址,这就可以改变CPU接下来执行的指令的地址为子程序的地址。
当CPU执行到“返回主程序”的指令时(对AVR来说就是ret)CPU将会出栈一个数据并写入PC。我们刚才提到,在进入子程序时,主程序的地址被入栈了;所以,此时出栈并写入PC的数据就是我们之前入栈的主程序的地址。于是,CPU就可以回到主程序的下一条指令的地址并执行了。
下面是一个演示在主程序调用子程序,并从子程序返回主程序的小程序。
注意入栈的是主程序中下一条需要执行的指令的地址(f1为0x8003,f2为0x8005)。
特例 - 修改返回地址
你应该注意到了,CPU依靠栈来确定返回的地址。如果栈的内容被错误的修改,CPU就会读到一个错误的返回地址。如果在调用子程序和返回时的SP不一样,CPU就会读取毫不相干的数据作为返回地址。这两种情况都会导致程序出错,并因为PC指向非法的地址而造成segment fault。
据我所知,没有高级语言支持开发者操作栈(这里说的是实际的栈,而不是数据类型的栈)或是修改栈指针SP,包括C语言。除非我们使用汇编或是内存映射之类的操作。
但是,在一些情况下,我们会想要要能修改栈与SP。想象有一个多线程程序,子程序A执行后会挂起并允许系统开始子程序B,此时系统便会保存A的数据并加载B的数据。子程序B执行后也会挂起并允许系统开始子程序A,此时系统便会保存B的数据并加载A的数据。
下面是一个演示在子程序A与子程序B之间进行上下文切换(Context Switch)的小程序。
子程序A与子程序B的数据被作为static变量储存在内存中。
子程序调用栈
框架
局部变量(子程序内部申明的变量)将被保存在栈中的一个区间,这个区间一般来说是在返回地址上面,如下图所示:
框架指针(Frame Pointer)
上文提到,CPU可以通过直接寻址或间接寻址的方式来读写数据。对于间接寻址,CPU将使用一个指针(基础地址)和一个额外的位移。间接寻址用于数据地址在编译时不知道的情况,其地址将在执行时实时计算出来。
因为调用子程序可能发生在任何时候,被任何主程序调用,并包括被自己调用(递归),因此我们无法在编译时就知道这些局部变量的地址。但是,在给这些局部变量分配空间前,我们可以通过当前SP来确定这些局部变量的起始地址。我们可以将此时的SP复制一份,然后再将局部变量入栈。而这个SP的复制品就可以作为我们的框架指针SP了。
通过这个指向框架起始(换句话说,也就是局部变量的起始位置)的SP指针,我们就可以读写框架中的数据,即局部变量了。
下面这个代码展示了如何读写局部变量2:
mov IX, SP ; Copy current SP into index register X (Note: not AVR assembly)
push v0, v1, v2, v3 ; Push local variables into stack (frame), SP is now at N-4 due to the push instructions, but IX is still at N+0
mov ACC, IX[-2] ; Read data pointed by IX with offset -2, which is (N+0) - 2 = N-2
AVR间接寻址
上面这个例子看起来没有问题,但是很遗憾,AVR做不到(这样的简便操作)。
如果栈向上生长,那么局部变量就会处在最初SP(刚进入子程序时)的上方,那么就需要支持正数偏移的间接寻址;如果栈向下生长,那么局部变量就会处在最初SP(刚进入子程序时)的下方,那么就需要支持负数偏移的间接寻址。AVR的栈向上生长,但是AVR只支持正数偏移的间接寻址。
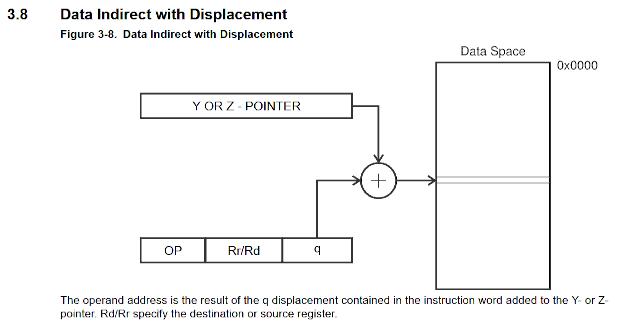

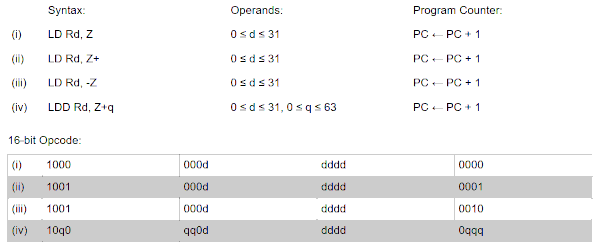
如AVR指令集手册所示,AVR支持使用寄存器Y(R29:R28)或寄存器Z(R31:R30)与额外0-63的偏移来读写内存。也就是说,AVR无法读写地址处于寄存器Y或寄存器Z之下的内存。
AVR-GCC框架指针
让我们写个简单的程序:创建一个局部变量stackdata。因为是局部变量,这个变量应该被保存在栈内。
#include <stdint.h>
void function() {
volatile uint8_t stackdata = 0xAB;
}
编译器会想办法优化我们的代码。变量会首先被储存在寄存器中,只有寄存器不够时才会使用内存,因为寄存器读写更快更方便。我们使用volatile关键字来防止编译器将这个变量放在寄存器来,以此方便我们观察。
avr-gcc -O3 1.c -o 1.out
avr-objdump -m avr2 -d 1.out > 1.asm
编译,再反汇编。
1.out: file format elf32-avr
Disassembly of section .text:
00000000 <function>:
0: cf 93 push r28
2: df 93 push r29
4: 1f 92 push r1
6: cd b7 in r28, 0x3d ; 61
8: de b7 in r29, 0x3e ; 62
a: 8b ea ldi r24, 0xAB ; 171
c: 89 83 std Y+1, r24 ; 0x01
e: 0f 90 pop r0
10: df 91 pop r29
12: cf 91 pop r28
14: 08 95 ret
AVR-GCC使用寄存器Y(R29:R28)作为框架指针FP。AVR-GCC ABI规定:R28与R29为callee-saved寄存器,也就是说主程序不期望子程序修改这些寄存器。如果子程序需要使用这些寄存器,那么就需要备份这些寄存器。
寄存器Y(R29:R28)和寄存器Z(R31:R30)都支持带位移的简介寻址,寄存器Y是callee-saved但是寄存器Z是caller-saved。也就是说,子程序可以随意修改寄存器Z而不需要备份,这就能节约一些时钟周期与程序空间。不过,AVR-GCC的开发者却决定使用寄存器Y作为FP。我猜测这是为了保留寄存器Z,因为寄存器Z是唯一支持从程序空间读取数据LPM (Load program memory)的寄存器。
在子程序的最开始使用push r28与push r29指令可以备份寄存器Y。要恢复寄存器Y,再程序最后(返回ret前)使用pop r29与pop r28指令。
AVR-GCC使用了push r1指令来为局部变量stackdata分配空间,这将会把R1当前的内容入栈并将SP下移一格。此时,R1的内容并不重要,只要这个指令能够下移SP一格,那就满足了在栈中分配1字节空间的需求,那就就可以了。
现在,我们就分配好了子程序框架所需要的空间。我们可以通过in r28, 0x3d与in r29, 0x3e指令将SP(地址0x3E:0x3D)复制到寄存器Y中,寄存器Y就可以被用作FP了。
上文提到,AVR的栈向下生长,SP指向下一个可写地址。因此,支持框架指针实际指向了框架的再往下一格的位置。
要读写变量stackvariable,我们可以使用间接寻址std y+1, r24指令:写寄存器Y指向的地址,偏移1。
下面展示了AVR-GCC进入子程序并分配框架空间。
子程序结束还原栈
再看一下之前的例子:
1.out: file format elf32-avr
Disassembly of section .text:
00000000 <function>:
0: cf 93 push r28
2: df 93 push r29
4: 1f 92 push r1
6: cd b7 in r28, 0x3d ; 61
8: de b7 in r29, 0x3e ; 62
a: 8b ea ldi r24, 0xAB ; 171
c: 89 83 std Y+1, r24 ; 0x01
e: 0f 90 pop r0
10: df 91 pop r29
12: cf 91 pop r28
14: 08 95 ret
调用call指令将PC里的下一条主程序的地址(也就是返回地址)入栈并修改PC到子程序地址;返回ret指令将栈内的返回地址写回PC。这里的关键是:call指令将返回地址入栈后,返回地址就在栈的顶端;所以,ret指令在执行时,返回地址也应该在栈的顶端。
因此,子程序在结束时返回前必须还原栈:子程序将多少数据入栈了,那么就需要将相同大小的数据出栈。换言之,执行ret指令前,SP的值必须和刚进入子程序时相等。
在如上例子中,pop r0指令被用来解除栈内的局部变量,以此还原栈。接下来,再使用pop r29与pop r28指令来还原寄存器Y。
编译器必须保持对SP的追踪。如果在使用ret指令时的SP与刚进入子程序时不一样,返回指令就会读到错误的数据作为返回地址。这会导致CPU返回到错误的地址,执行错误的程序。PC上的话这就是触发segment fault。
参考:如果栈向上生长,或是CPU支持负数位移的间接寻址的话,框架指针将不需要被移动,所以就可以被拿来当作栈指针的备份。这样的话,编译器就不用追踪SP了,只要在子程序末尾将FP的值写回SP就可以轻松还原栈了。这样生成的代码将会更简洁,也允许更灵活的栈操作。
// 支持负数位移
FP = SP; // at data -1 (return address)
push(data0);
do_soemthing(FP[-1]); //data0
if (cond) {
push(data1); // Less push
do_soemthing(FP[-2]); //data1
} else {
push(data1); // More push
push(data2);
do_soemthing(FP[-2]); //data1
if (cond) {
push(data3); // Even more push
do_soemthing(FP[-4]); //data3
}
}
SP = FP;
return;
// 不支持负数位移
push(data0); // SP at return address + 1
FP = SP;
do_soemthing(FP[0]); //data0
if (cond) {
push(data1); // Less push; SP at return address + 2
FP = SP;
do_soemthing(FP[0]); //data1
pop(); // SP at return address + 1
} else {
push(data1); // More push; SP at return address + 2
push(data2); // SP at return address + 3
FP = SP;
do_soemthing(FP[1]); //data1
if (cond) {
push(data3); // Even more push; SP at return address + 4
FP = SP;
do_soemthing(FP[0]); //data3
pop(); // SP at return address + 3
}
pop(); // SP at return address + 2
pop(); // SP at return address + 1
}
pop(); // SP at return address + 0
return;
AVR-GCC分配栈
在上面的例子中,AVR-GCC通过push X指令来给局部变量分配了1字节的空间。
接下来AVR-GCC将给局部变量分配2字节的空间:
#include <stdint.h>
#define SIZE 2
void function() {
volatile uint8_t stackdata[SIZE];
stackdata[SIZE-1] = 0xFF;
}
00000000 <function>:
0: cf 93 push r28
2: df 93 push r29
4: 00 d0 rcall .+0 ; 0x6 - Relative call: to the next line (so, no effect on PC)
6: cd b7 in r28, 0x3d ; 61
8: de b7 in r29, 0x3e ; 62
a: 8f ef ldi r24, 0xFF ; 255
c: 8a 83 std Y+2, r24 ; 0x02
e: 0f 90 pop r0
10: 0f 90 pop r0
12: df 91 pop r29
14: cf 91 pop r28
16: 08 95 ret
在这个例子里,AVR-GCC没有使用两个push指令来分配2字节的空间,而是使用了一个rcall .+0(调用子程序,相对地址)指令。
如果你经常写Python,你可能认为计算机会有调用了几层子程序的概念,就像是你会在代码前空出特定的缩进一样(实际上,高级语言使用软件的方式来追踪调用)。但是,这并不是AVR(和一大票其他的架构)的工作方式。CPU不会追踪有几层调用,CPU内部没有任何寄存器或是电路被用来为调用计数。call指令只会“单纯地”将PC入栈并修改PC,ret指令只会“单纯地”将返回地址出栈并写入PC。
AVR的程序地址为16比特长,所以,入栈/出栈返回地址将会消耗/释放2字节的栈空间,并将SP下移/上移2。相比较于使用两个push指令,AVR-GCC决定使用一条rcall,这同样能达到分配2字节的栈空间,但是只消耗了1个程序空间。
如果我们有更多的局部变量呢?比如说,我们有128字节的局部变量,这将远超AVR间接寻址的64字节的最大位移。下面展示了一个有128字节的变量的程序:
#include <stdint.h>
#define SIZE 128
void function() {
volatile uint8_t stackdata[SIZE];
stackdata[SIZE-1] = 0xFF;
}
00000000 <function>:
0: cf 93 push r28
2: df 93 push r29
4: cd b7 in r28, 0x3d ; 61
6: de b7 in r29, 0x3e ; 62
8: c0 58 subi r28, 0x80 ; 128
a: d1 09 sbc r29, r1
c: 0f b6 in r0, 0x3f ; 63
e: f8 94 cli
10: de bf out 0x3e, r29 ; 62
12: 0f be out 0x3f, r0 ; 63
14: cd bf out 0x3d, r28 ; 61
16: 8f ef ldi r24, 0xFF ; 255
18: c0 58 subi r28, 0x80 ; 128
1a: df 4f sbci r29, 0xFF ; 255
1c: 88 83 st Y, r24
1e: c0 58 subi r28, 0x80 ; 128
20: d0 40 sbci r29, 0x00 ; 0
22: c0 58 subi r28, 0x80 ; 128
24: df 4f sbci r29, 0xFF ; 255
26: 0f b6 in r0, 0x3f ; 63
28: f8 94 cli
2a: de bf out 0x3e, r29 ; 62
2c: 0f be out 0x3f, r0 ; 63
2e: cd bf out 0x3d, r28 ; 61
30: df 91 pop r29
32: cf 91 pop r28
34: 08 95 ret
让我们一步一步来分析这个代码:
0: cf 93 push r28
2: df 93 push r29
4: cd b7 in r28, 0x3d ; 61
6: de b7 in r29, 0x3e ; 62
寄存器Y入栈并将当前SP写入FP(寄存器Y)。
8: c0 58 subi r28, 0x80 ; 128
a: d1 09 sbc r29, r1
c: 0f b6 in r0, 0x3f ; 63
e: f8 94 cli
10: de bf out 0x3e, r29 ; 62
12: 0f be out 0x3f, r0 ; 63
14: cd bf out 0x3d, r28 ; 61
在FP中计算为128字节的局部变量分配空间后的栈的地址。因为在C源码中我们并没有给这些局部变量赋值,所以我们不需要将实际的值入栈,只要移动SP就可以了。既然有128字节的局部变量,那么就将SP往下移动128。
要下移128,我们将FP(等于当前FP)减去128。AVR-GCC首先使用subi r28, 0x80(减去立即数)来为FP的低位减去128(注意SP和FP都是16比特长度的,分高低两位)。因为在16比特数据上做8比特操作有溢出风险,所以,接下来AVR-GCC还会使用sbc r29, r1 (减去寄存器与进位)来为高位减0和进位。AVR-GCC ABI规定,R1永远为0。
此时,FP已经指向框架的低端并可以用来读写整个框架了(展示忽略最大位移限制),我们还是需要将FP写回SP来真正地分配栈空间。这样,在调用更下级的子程序或是在中断发生时,新的SP才能有效。
因为SP有两个字节长,我们需要两次分别写低位和高位。很遗憾,除了像是计时器的特殊寄存器外,AVR不支持同时写多字节的数据。这就带来了另一个风险,SP写道一半的时候发生了中断。在SREG(地址0x3F)中有一个比特可以开关全局中断,我们可以使用cli指令来暂时关掉中断。操作结束后,我们再恢复SREG就可以恢复之前中断的状况了。
编译器并不知道此时是否开启了中断,AVR-GCC也不能(也不该)通过我们的代码在编译时猜测中断的状况。因此,编译器会在关闭中断前使用R0来备份SREG,之后再将R0写回SREG来恢复之前中断的状况。
stackdata[SIZE-1] = 0xFF; // stackdata[127] = 0xFF
16: 8f ef ldi r24, 0xFF ; 255
18: c0 58 subi r28, 0x80 ; 128
1a: df 4f sbci r29, 0xFF ; 255
1c: 88 83 st Y, r24
1e: c0 58 subi r28, 0x80 ; 128
20: d0 40 sbci r29, 0x00 ; 0
接下来,我们将把常数0xFF写入数组的最后一位,也就是stackdata[127]。
AVR-GCC先通过ldi r24, 0xFF指令将这个常数载入R24。
因为间接寻址最大支持64字节位移,但是我们在这里需要的位移显然大于这个限制了。因此,AVR-GCC计算了stackdata[127]的地址并决定使用不带位移的间接寻址,也就是st Y, r24。
要计算数据的地址,我们可以在FP上加上数据的偏移量,也就是128,或0x80。注意,因为SP指向了下一个可写地址,所以栈的地址实际上应该是SP+1,stackdata[127]就应该是SP+1+127 = SP+128 = SP+0x80。
因为AVR的数据总线是16比特长的,所以我们需要在SP上加上0x0080,并像之前算FP时一样考虑可能的进位问题。
AVR指令集并没有adic(加上立即数与进位)这样的指令来让我们做16比特立即数加法。一个解决方案是将高位写入一个临时寄存器后使用adc(加上寄存器与进位)指令;另一个办法是使用sbci(减去立即数与进位)指令并使用要加的数的负数:+0x0080 = -0xFF80。因为在编译时我们就知道这个加数了,所以编译器可以在编译时计算出它的负数并使用sbci指令。于是,最终结果就是:subi r28, 0x80计算低位,sbci r29, 0xFF计算高位。
最后,在完成读写后,我们需要恢复FP,将这个128的位移减回去:subi r28, 0x80,sbci r29, 0x00。
22: c0 58 subi r28, 0x80 ; 128
24: df 4f sbci r29, 0xFF ; 255
26: 0f b6 in r0, 0x3f ; 63
28: f8 94 cli
2a: de bf out 0x3e, r29 ; 62
2c: 0f be out 0x3f, r0 ; 63
2e: cd bf out 0x3d, r28 ; 61
在返回主程序前,我们还要恢复栈。显然,执行128次pop指令是不现实的。我们通过直接将FP加上128再写回SP的方法让SP上移了128,达到了恢复栈的目的。注意,这里分两步写了SP,所以我们需要再次临时禁用中断。
30: df 91 pop r29
32: cf 91 pop r28
34: 08 95 ret
恢复寄存器Y并返回。
在上面的例子中,我们看到AVR-GCC必须执行一些写和恢复全局中断状态的额外操作来防止在SP写一半时发生中断。
AVR-GCC不能假设中断的情况,但是我们作为开发者知道中断是否打开。如果我们不需要使用中断,或是中断未打开,我们可以添加__attribute__((OS_main))来告诉GCC忽略中断:
#include <stdint.h>
#define SIZE 128
__attribute__((OS_main)) void function() {
volatile uint8_t stackdata[SIZE];
stackdata[SIZE-1] = 0xFF;
}
00000000 <function>:
0: cd b7 in r28, 0x3d ; 61
2: de b7 in r29, 0x3e ; 62
4: c0 58 subi r28, 0x80 ; 128
6: d1 09 sbc r29, r1
8: de bf out 0x3e, r29 ; 62
a: cd bf out 0x3d, r28 ; 61
c: 8f ef ldi r24, 0xFF ; 255
e: c0 58 subi r28, 0x80 ; 128
10: df 4f sbci r29, 0xFF ; 255
12: 88 83 st Y, r24
14: c0 58 subi r28, 0x80 ; 128
16: d0 40 sbci r29, 0x00 ; 0
18: c0 58 subi r28, 0x80 ; 128
1a: df 4f sbci r29, 0xFF ; 255
1c: 0f b6 in r0, 0x3f ; 63
1e: f8 94 cli
20: de bf out 0x3e, r29 ; 62
22: 0f be out 0x3f, r0 ; 63
24: cd bf out 0x3d, r28 ; 61
26: 08 95 ret
可以看到代码变少了。
主程序调用栈
再上一个章节中,我们研究了子程序的栈。接下来,让我们来看看主程序的栈。
在调用子程序前,我们需要找到一个方法将参数传递给子程序。AVR-GCC使用了一系列的寄存器来达成这个目标。
#include <stdint.h>
extern uint8_t function(uint8_t, uint8_t);
void main() {
volatile uint8_t x = function(0x81, 0x80);
}
// extern告诉编译器这个子程序会在link的时候添加,现在只要知道子程序接收多少参数和每个参数的类型,不要考虑子程序的内容
00000000 <main>:
0: cf 93 push r28
2: df 93 push r29
4: 1f 92 push r1
6: cd b7 in r28, 0x3d ; 61
8: de b7 in r29, 0x3e ; 62
a: 60 e8 ldi r22, 0x80 ; 128
c: 81 e8 ldi r24, 0x81 ; 129
e: 00 d0 rcall .+0 ; 0x10 <main+0x10> 实际地址会在link时添加
10: 89 83 std Y+1, r24 ; 0x01
12: 0f 90 pop r0
14: df 91 pop r29
16: cf 91 pop r28
18: 08 95 ret
上面的例子中,我们给最后一个参数赋值0x80,给倒数第二个参数赋值0x81。再反汇编代码中,AVR-GCC使用R24传递第一个参数,使用R22传递第二个参数。
参数执行顺序
C语言标准并没有明确规定参数的执行顺序与参数的入栈(或复制到传递用寄存器)的顺序。不同的编译器,甚至不同的版本,可能会有不同的顺序。
AVR-GCC从右到左执行与入栈(或复制)参数。也就是说,最后一个参数会被首先执行与入栈,然后是倒数第二个参数……
uint8_t x = 0b00000001;
void p1() { x =<< 1; } // Shift left
void p2() { x += 1; } // Plus 1
void main() {
function(
p1(), // Evaluated first: 0b00000001 << 1 = 0b00000010
p2() // Evaluated second: 0b00000010 + 1 = 0b00000011
);
print(x);
}
Get 0b00000011 (错误)
uint8_t x = 0b00000001;
void p1() { x =<< 1; } // Shift left
void p2() { x += 1; } // Plus 1
void main() {
function(
p1(), // Evaluated second: 0b00000010 << 1 = 0b00000100
p2() // Evaluated first: 0b00000001 + 1 = 0b00000010
);
print(x);
}
Get 0b00000100 (正确)
参数传递顺序
根据AVR-GCC ABI,AVR-GCC将寄存器看作寄存器对。寄存器R25到R8通过从高到低的顺序以此使用。
如果第一个参数是8比特长的话,就会使用R24;如果是16比特长,就会使用R25:R24;如果是32比特长,就会使用R25:R22;如果是64比特长,就会使用R25:R18。
同样的规则作用于剩下的寄存器与剩下的参数。如果第一个参数是32比特长,那么R25:R22就被占用了。如果第二个参数是8比特长的话,第二个参数就会使用R20;如果是16比特长,就会使用R21:R20;如果是32比特长,就会使用R21:R18;如果是64比特长,就会使用R21:R14。
如果寄存器不够用了,剩下的参数就会被通过栈传递。和寄存器传递不同,8比特的参数在栈传递时不会有空出。
下面代码展示了两个参数通过寄存器传递:第一个8-bit参数在R25:R24,第二个8-bit参数在R23:R22。高位没有被使用。
extern uint8_t function(uint8_t, uint8_t);
void main() {
volatile uint8_t x = function(0x81, 0x80);
}
a: 60 e8 ldi r22, 0x80 ; 128
c: 81 e8 ldi r24, 0x81 ; 129
e: 00 d0 rcall .+0
下面代码展示了三个参数通过寄存器传递:第一个64-bit参数在R25:R18,第二个64-bit参数在R17:R10,第三个16-bit参数在R9:R8。
extern uint8_t function(uint64_t, uint64_t, uint16_t);
void main() {
volatile uint8_t x = function(0x82, 0x81, 0x80);
}
1e: 80 e8 ldi r24, 0x80 ; 128
20: 88 2e mov r8, r24 ; Only upper registers (R16-R31) can be used to load constant
22: 91 2c mov r9, r1 ; r1 is always 0
24: 91 e8 ldi r25, 0x81 ; 129
26: a9 2e mov r10, r25
28: b1 2c mov r11, r1
2a: c1 2c mov r12, r1
2c: d1 2c mov r13, r1
2e: e1 2c mov r14, r1
30: f1 2c mov r15, r1
32: 00 e0 ldi r16, 0x00 ; 0
34: 10 e0 ldi r17, 0x00 ; 0
36: 22 e8 ldi r18, 0x82 ; 130
38: 30 e0 ldi r19, 0x00 ; 0
3a: 40 e0 ldi r20, 0x00 ; 0
3c: 50 e0 ldi r21, 0x00 ; 0
3e: 60 e0 ldi r22, 0x00 ; 0
40: 70 e0 ldi r23, 0x00 ; 0
42: 80 e0 ldi r24, 0x00 ; 0
44: 90 e0 ldi r25, 0x00 ; 0
46: 00 d0 rcall .+0
下面代码展示了参数传递:第一个64-bit参数在R25:R18,第二个64-bit参数在R17:R10,第三个64-bit参数在栈中,第四个8-bit参数在栈中,第五个8-bit参数在栈中。
extern uint8_t function(uint64_t, uint64_t, uint64_t, uint8_t, uint8_t);
void main() {
volatile uint8_t x = function(0x83, 0x82, 0x81, 0x80, 0x40);
}
1a: 80 e4 ldi r24, 0x40 ; 64
1c: 8f 93 push r24
1e: 80 e8 ldi r24, 0x80 ; 128
20: 8f 93 push r24
22: 1f 92 push r1
24: 1f 92 push r1
26: 1f 92 push r1
28: 1f 92 push r1
2a: 1f 92 push r1
2c: 1f 92 push r1
2e: 1f 92 push r1
30: 81 e8 ldi r24, 0x81 ; 129
32: 8f 93 push r24
34: 82 e8 ldi r24, 0x82 ; 130
36: a8 2e mov r10, r24
38: b1 2c mov r11, r1
3a: c1 2c mov r12, r1
3c: d1 2c mov r13, r1
3e: e1 2c mov r14, r1
40: f1 2c mov r15, r1
42: 00 e0 ldi r16, 0x00 ; 0
44: 10 e0 ldi r17, 0x00 ; 0
46: 23 e8 ldi r18, 0x83 ; 131
48: 30 e0 ldi r19, 0x00 ; 0
4a: 40 e0 ldi r20, 0x00 ; 0
4c: 50 e0 ldi r21, 0x00 ; 0
4e: 60 e0 ldi r22, 0x00 ; 0
50: 70 e0 ldi r23, 0x00 ; 0
52: 80 e0 ldi r24, 0x00 ; 0
54: 90 e0 ldi r25, 0x00 ; 0
56: 00 d0 rcall .+0
注意到:
- R9:R8未被使用。因为第三个参数太大了,没办法使用剩下的寄存器传输,所以就是用了栈传输。第四个与第五个参数虽然能被放入剩下的寄存器中,但是将它们放在第三个参数后(寄存器中)显然更合规一些。
- 栈传递的两个8比特数据之间没有空出。
- 参数的高位会比低位跟早入栈。因为AVR的栈向下生长,因此先入栈的高位会比后入栈的低位获得更高的内存地址。